
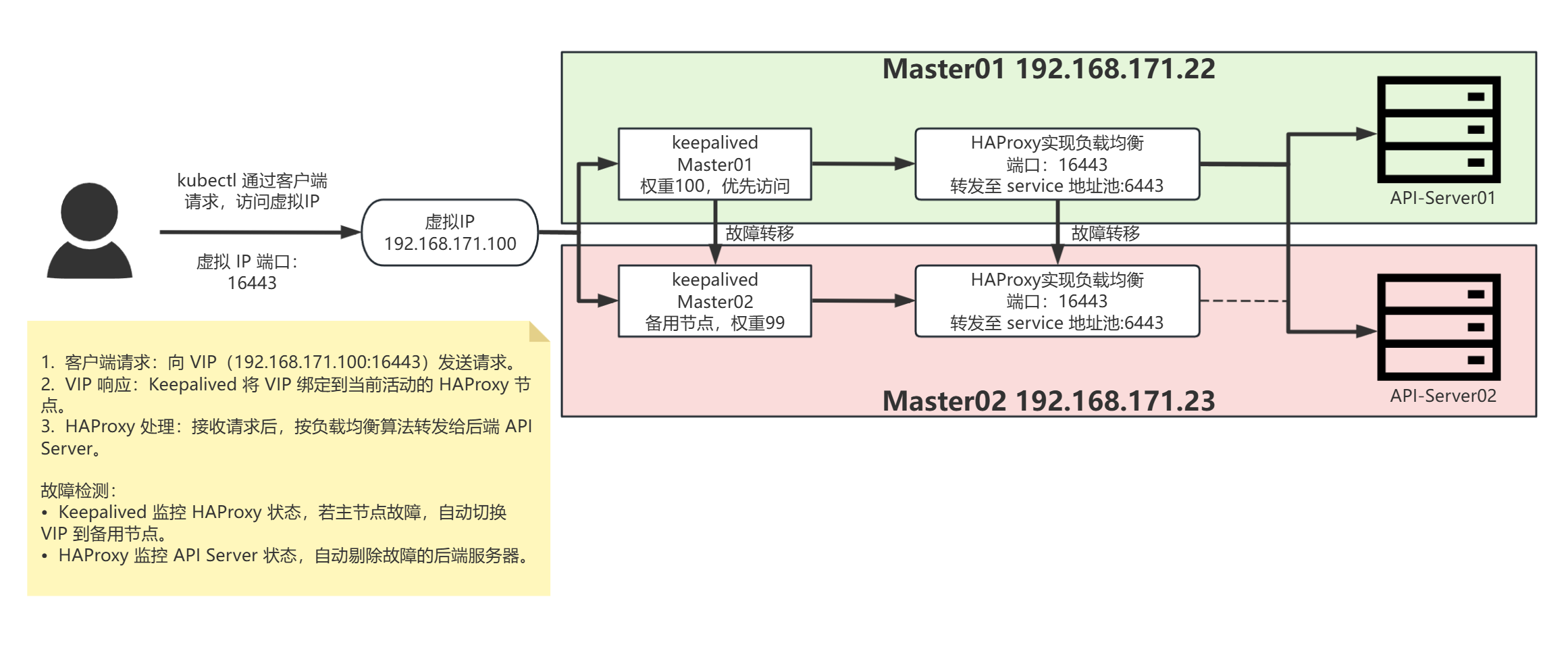
当 k8s-master01 挂掉时:
Keepalived 自动切换 VIP:
主节点故障,备用节点的 Keepalived 检测到主节点失效,将 VIP(192.168.171.100)绑定到自己的网卡。
备用节点的 HAProxy 开始监听 VIP:16443(因配置中
frontend main *:16443监听所有 IP,包括 VIP)。
HAProxy 继续工作:
备用节点的 HAProxy 检查后端服务器池:
k8s-master01(192.168.171.22)已挂掉,健康检查失败,标记为不可用。k8s-master02(192.168.171.23)、k8s-master03(192.168.171.24)若正常运行,HAProxy 会将请求转发给它。
流量转发逻辑不变,仅后端服务器列表中剔除故障的
k8s-master01。
关键条件:
备用节点必须运行 HAProxy:若 HAProxy 仅部署在主节点(错误配置),则故障后无法工作。
HAProxy 配置一致:两台节点的 HAProxy 配置文件需完全相同(包括后端服务器池、端口监听等)。
k8s-master02 自身正常:若
k8s-master02同时故障,HAProxy 会因后端无可用服务器返回 503 错误。
一、基础环境配置(所有节点)
CentOS 7 更换 yum 源:
# 下载阿里云的repo文件
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
# 清空旧yum缓存并重建新缓存
yum clean all && yum makecache
# 更新软件包
yum update -y修改主机名与解析主机名:
# 修改主机名(各节点执行对应的命令)
# k8s-master01
hostnamectl set-hostname k8s-master01
# k8s-master02
hostnamectl set-hostname k8s-master02
...
# 主机名解析文件(所有节点执行)
cat << EOF >> /etc/hosts
192.168.171.22 k8s-master01
192.168.171.23 k8s-master02
192.168.171.24 k8s-master03
192.168.171.25 k8s-node01
192.168.171.26 k8s-node02
EOF关闭防火墙 & 关闭SELINUX
# 关闭防火墙,禁止开机自启
systemctl stop firewalld && systemctl disable firewalld
# 查看防火墙状态
systemctl status firewalld
# 非交互式关闭(推荐)
sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 重启生效
reboot
# 临时关闭,无需重启
setenforce 0
# 查看状态
sestatus关闭swap
# 非交互式关闭(注释/etc/fstab中的swap行)
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 重启生效
reboot
# 临时关闭
swapoff -a
# 查看swap
free -h更新内核:
# Centos 7已经于2024年底停止更新,第三方和官方仓库都清空了 kernel 更新。需要进行手动更新。
# 从网址https://dl.lamp.sh/kernel/el7找到最新版
# 下载最新版:
wget https://dl.lamp.sh/kernel/el7/kernel-ml-6.9.10-1.el7.x86_64.rpm
wget https://dl.lamp.sh/kernel/el7/kernel-ml-devel-6.9.10-1.el7.x86_64.rpm
# 检查当前的启动的 kernel:
grub2-editenv list
# saved_entry=CentOS Linux (3.10.0-1160.119.1.el7.x86_64) 7 (Core)
# 本地安装 kernel:
yum localinstall -y kernel-ml-6.9.10-1.el7.x86_64.rpm kernel-ml-devel-6.9.10-1.el7.x86_64.rpm
# 安装成功后,通过命令设置默认启动的内核:
grub2-set-default 'CentOS Linux (6.9.10-1.el7.x86_64) 7 (Core)'
# 重启
shutdown -r 0
# 再次查看当前的启动的 kernel:
grub2-editenv list关闭numa
# NUMA 会优先将内存分配给本地处理器,可能导致节点内不同 CPU 核心的内存负载不均
# 关闭 NUMA 主要是为了 简化内存管理 和 提升容器调度的稳定性
# 备份
cp /etc/default/grub{,.bak}
# 在配置GRUB_CMDLINE_LINUX=项末尾添加 numa=off
sed -i 's/^\(GRUB_CMDLINE_LINUX="[^"]*\)"$/\1 numa=off"/' /etc/default/grub时间同步
# 查看服务状态
systemctl status chronyd
# 查看同步状态
chronyc tracking
# 安装Chrony(CentOS7默认已安装)
yum -y install chrony
# 修改配置使用阿里云时间服务器
sed -i 's/^server/#server/g' /etc/chrony.conf # 注释默认服务
cat << EOF >> /etc/chrony.conf
server ntp1.aliyun.com iburst
server time1.aliyun.com iburst
server time2.aliyun.com iburst
EOF
# 重启chronyd服务
systemctl restart chronyd
# 设置chronyd服务开机自启
systemctl enable chronyd路由转发及网桥过滤
# k8s路由转发配置文件
cat << EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
# 加载网桥过滤模块
modprobe br_netfilter
# 载入配置使生效
sysctl -p /etc/sysctl.d/k8s.conf
sysctl --system安装 ipset & ipvsadm
# 安装ipset和ipvsadm
yum install ipset ipvsadm -y
# 创建ipvs模块加载脚本
cat << EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack # 内核 5.0 以下改为 nf_conntrack_ipv4
modprobe -- br_netfilter
EOF
# 赋予执行权限
chmod +x /etc/sysconfig/modules/ipvs.modules
# 执行脚本加载模块
bash /etc/sysconfig/modules/ipvs.modules
# 检测模块是否加载成功
lsmod | grep -e ip_vs -e nf_conntrack二、安装Docker & cri-dockerd(所有节点)
# 卸载旧版本 Docker
yum remove -y \
docker-ce \
docker-ce-cli \
containerd.io \
docker-buildx-plugin \
docker-compose-plugin \
docker-ce-rootless-extras \
docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine \
podman \
runc
# 配置 Docker 阿里云镜像源
curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache # 生成缓存
# 安装 Docker-ce
# yum list docker --showduplicates | sort -i
yum install -y docker-ce
# 配置Docker cgroup驱动(与 Kubernetes 兼容,使用 systemd 驱动)
mkdir -p /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
systemctl start docker && systemctl enable docker # 启动并启用Docker服务
docker version # 验证安装结果安装 cri-dockerd
cd /usr/local/src/
# 下载cri-dockerd RPM包(确保与Kubernetes版本兼容)
wget -O /usr/local/src/cri-dockerd-0.3.14-3.el7.x86_64.rpm https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.14/cri-dockerd-0.3.14-3.el7.x86_64.rpm
rpm -ivh /usr/local/src/cri-dockerd-0.3.14-3.el7.x86_64.rpm # 安装
# 修改服务配置(指定 CNI 网络插件和 pause 镜像地址)
cp /usr/lib/systemd/system/cri-docker.service /usr/lib/systemd/system/cri-docker.service.bak
sed -i 's@^ExecStart=.*$@ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9@g' /usr/lib/systemd/system/cri-docker.service
systemctl daemon-reload
systemctl start cri-docker.service && systemctl enable cri-docker.service
systemctl status cri-docker.service三、Kubernetes组件部署(所有节点)
Kubernetes 集群核心组件:
# 配置 Kubernetes 阿里云镜像源(加速组件下载)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 安装Kubernetes组件(--disableexcludes避免版本冲突)
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl daemon-reload && systemctl start kubelet.service && systemctl enable kubelet # 启用kubelet服务(开机自启) # k8s命令太多,务必要配置补全
# 操作节点:Master
yum install bash-completion -y
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc四、高可用组件部署(Master 节点)
Keepalived(VIP 管理)
作用:为主节点分配虚拟 IP(VIP: 192.168.171.100),实现故障转移。
# 安装
yum install keepalived -y
# 备份配置文件
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
# 日志文件:/var/log/massages
# 配置 keepalived.conf
vim /etc/keepalived/keepalived.confMaster01:
# 全局定义部分
global_defs {
router_id k8s # 标识本Keepalived实例的唯一名称,集群内通常保持一致
}
# VRRP实例配置
vrrp_instance VI_1 {
state MASTER # 初始状态为主节点(优先级高的节点)
interface ens33 # 使用的网络接口(网卡)名
virtual_router_id 51 # 虚拟路由ID,必须与备用节点相同
priority 100 # 优先级值(0-255),值越高越优先成为 Master
advert_int 1 # 发送VRRP通告的间隔(秒)
authentication { # 节点间认证配置
auth_type PASS # 认证类型为密码
auth_pass 123321 # 认证密码,必须与备用节点相同
}
virtual_ipaddress { # 定义虚拟IP地址(VIP)
192.168.171.100 # 此IP会在主备节点间自动漂移
}
track_script { # 关联健康检查脚本
chk_haproxy # 监控HAProxy状态
}
}
# 健康检查脚本:监控HAProxy服务状态
vrrp_script chk_haproxy {
script "killall -0 haproxy" # 检查haproxy进程是否存在(-0参数只做检查不终止)
interval 1 # 检查间隔为1秒
fall 3 # 连续3次失败才认定服务不可用
rise 2 # 连续2次成功才恢复服务状态
weight -2 # 如果检查失败,当前节点优先级降低2
}Master02、Master03:
# 全局定义部分(与主节点相同)
global_defs {
router_id k8s # 必须与主节点保持一致
}
# VRRP实例配置(关键区别在于优先级)
vrrp_instance VI_1 {
state MASTER # 初始状态也设为主(但优先级更高)
interface ens33 # 必须与主节点相同的网络接口(网卡)
virtual_router_id 51 # 必须与主节点相同的虚拟路由ID
priority 99 # 优先级比主节点少1,因此不会成为活动 Master
advert_int 1 # VRRP通告间隔(与主节点一致)
authentication { # 认证配置(与主节点完全相同)
auth_type PASS
auth_pass 123321
}
virtual_ipaddress { # 相同的VIP配置
192.168.171.100
}
track_script { # 相同的健康检查脚本
chk_haproxy
}
}
# 健康检查脚本(与主节点完全相同)
vrrp_script chk_haproxy {
script "killall -0 haproxy" # 检查haproxy进程状态
interval 1 # 每秒检查一次
fall 3 # 连续3次失败才触发状态切换
rise 2 # 连续2次成功才恢复正常
weight -2 # 检查失败时优先级降低2
} # 启动 & 开机自启
systemctl start keepalived && systemctl enable keepalived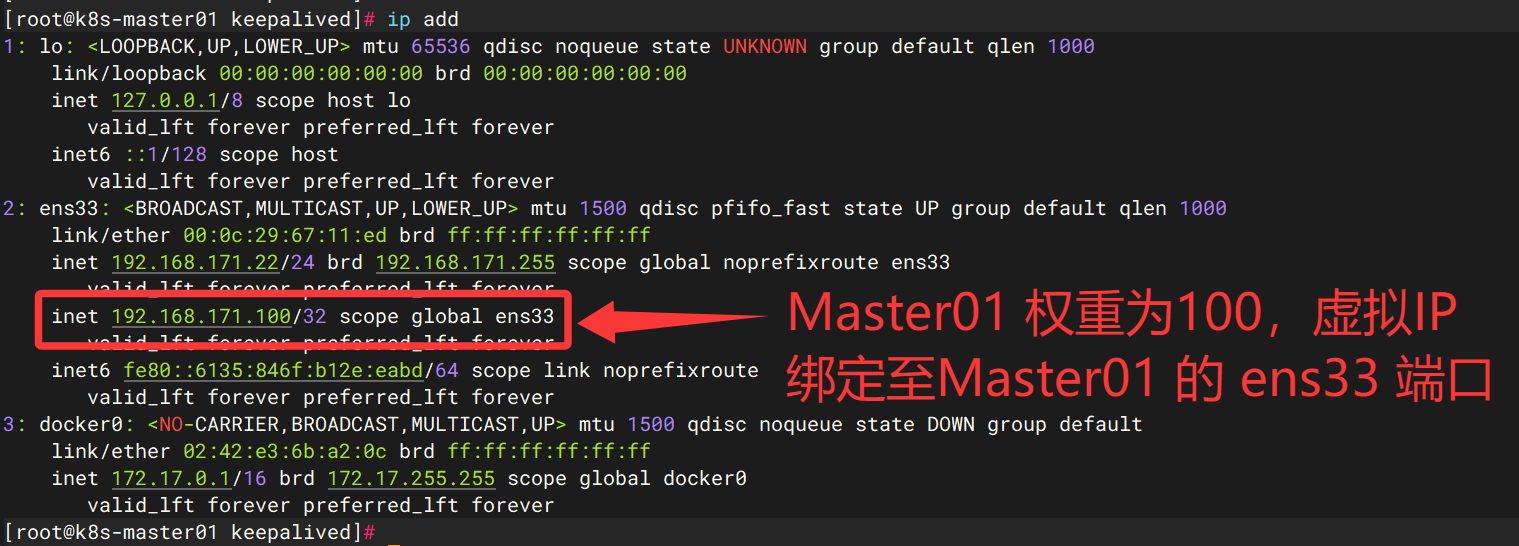
HAProxy(节点负载均衡)
作用:转发客户端请求到多个 Master 节点,避免单点故障。
# 安装
yum install haproxy -y
# 备份配置文件
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
vim /etc/haproxy/haproxy.cfg #---------------------------------------------------------------------
# 全局设置
#---------------------------------------------------------------------
global
log 127.0.0.1 local2 # 将日志发送到本地syslog的local2 facility
# 需要在/etc/syslog.conf中配置local2指向/var/log/haproxy.log
chroot /var/lib/haproxy # 改变进程根目录,增强安全性
pidfile /var/run/haproxy.pid # 进程PID文件位置
maxconn 4000 # 最大并发连接数
user haproxy # 运行进程的用户
group haproxy # 运行进程的用户组
daemon # 以守护进程模式运行
# 启用统计信息Unix套接字
stats socket /var/lib/haproxy/stats # 通过Unix域套接字获取内部统计信息
#---------------------------------------------------------------------
# 默认设置 - 所有frontend/backend继承的配置
#---------------------------------------------------------------------
defaults
mode tcp # 工作在TCP模式(适用于Kubernetes API Server)
log global # 使用global部分定义的日志配置
option dontlognull # 不记录空连接日志
retries 3 # 连接失败后的重试次数
timeout http-request 10s # HTTP请求超时时间
timeout queue 1m # 队列中等待的超时时间
timeout connect 10s # 连接到后端服务器的超时时间
timeout client 1m # 客户端空闲超时时间
timeout server 1m # 服务器空闲超时时间
timeout http-keep-alive 10s # HTTP Keep-Alive超时时间
timeout check 10s # 健康检查超时时间
maxconn 3000 # 每个进程的最大连接数
#---------------------------------------------------------------------
# 前端配置 - 接收客户端请求
#---------------------------------------------------------------------
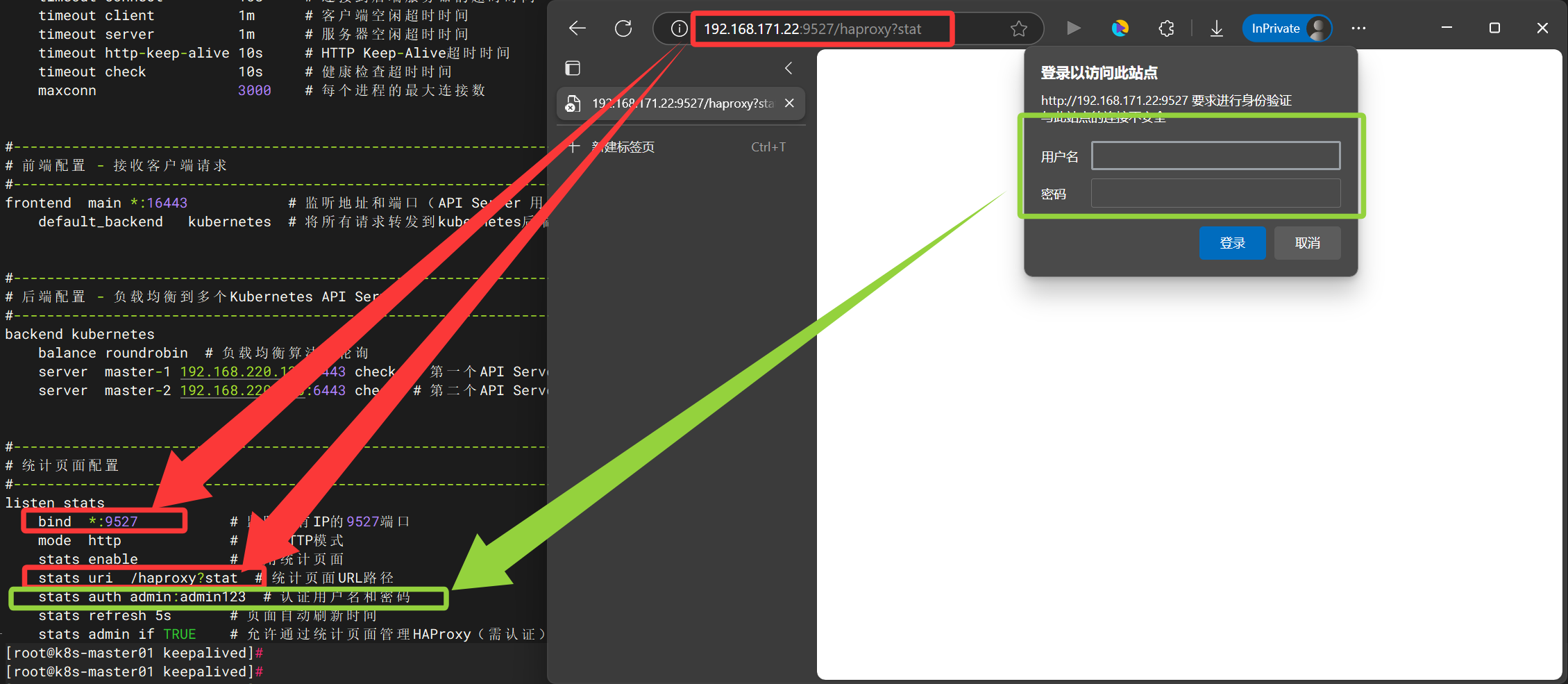
frontend main *:16443 # 监听地址和端口(API Server 用了 6443,这里用 16443)
default_backend kubernetes # 将所有请求转发到kubernetes后端
#---------------------------------------------------------------------
# 后端配置 - 负载均衡到多个Kubernetes API Server
#---------------------------------------------------------------------
backend kubernetes
balance roundrobin # 负载均衡算法:轮询
server k8s-master01 192.168.171.22:6443 check # 第一个API Server节点,启用健康检查
server k8s-master02 192.168.171.23:6443 check # 第二个API Server节点,启用健康检查
server k8s-master03 192.168.171.24:6443 check # 第三个API Server节点,启用健康检查
#---------------------------------------------------------------------
# 统计页面配置,可以通过宿主机IP地址+端口,实现访问
#---------------------------------------------------------------------
listen stats
bind *:9527 # 监听所有IP的9527端口
mode http # 使用HTTP模式
stats enable # 启用统计页面
stats uri /haproxy?stat # 统计页面URL路径
stats auth admin:admin123 # 认证用户名和密码
stats refresh 5s # 页面自动刷新时间
stats admin if TRUE # 允许通过统计页面管理HAProxy(需认证) # 检查语法
haproxy -f /etc/haproxy/haproxy.cfg -c
systemctl start haproxy && systemctl enable haproxy
systemctl status haproxy
netstat -tunlp | grep -i haproxy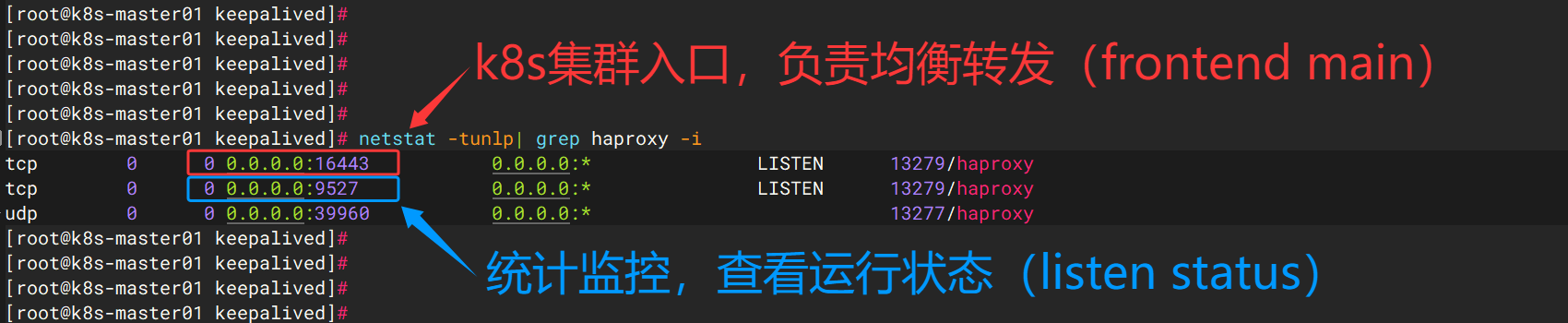
坑(很多人报错 [kubelet-check] Initial timeout of 40s passed. ):
原因:
HAProxy 的协议模式配置错误:HAProxy 用 HTTP 模式 转发了 HTTPS 流量(API Server 的 6443 端口是 HTTPS 协议),导致协议不匹配,最终返回 “HTTP 响应给 HTTPS 客户端” 的错误。
排查方法:
在 master 节点执行以下命令,检查虚拟 IP 192.168.171.100:16443 是否能正确返回 HTTPS 响应(而非 HTTP 错误):
curl -v https://192.168.171.100:16443正常输出特征:会显示 SSL connection using TLSv1.3 或 TLSv1.2,并打印 API Server 的证书信息(如 subject: CN=kube-apiserver),无 “HTTP response to HTTPS client” 错误。
解决方案:将 HAProxy 改为 TCP 模式(四层转发),直接透传 HTTPS 流量,不解析应用层协议,确保协议一致性。
五、K8s 集群初始化
Master01:
# 生成初始化配置模板
kubeadm config print init-defaults > /root/kubeadm-init.yaml
# 自定义初始化配置文件(关键参数修正)
vim /root/kubeadm-init.yaml apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.171.22 # 修正为 Master 实际 IP
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock # 更换为 cri-dockerd
imagePullPolicy: IfNotPresent
name: k8s-master01 # 修改主机名(注意:创建之后不可改变)
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.171.100:16443" # 添加控制平面入口地址
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.k8s.io # 如果拉不了,换成阿里源:registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.28.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 添加 Pod 网段(Flannel默认使用)
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration # kube-proxy 配置
mode: ipvs # 负载均衡模式(推荐IPVS,需提前加载ipvs内核模块)
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration # kubelet 配置
cgroupDriver: systemd # 与 Docker/cri-dockerd 的 cgroup 驱动一致(必填) cd /root
kubeadm config images list --config /root/kubeadm-init.yaml # 列出所需镜像
kubeadm config images pull --config /root/kubeadm-init.yaml # 拉取镜像
# 初始化Master节点(忽略系统验证错误,如 Swap 已禁用可移除--ignore-preflight-errors=SystemVerification 参数 )
kubeadm init --config /root/kubeadm-init.yaml --ignore-preflight-errors=SystemVerification 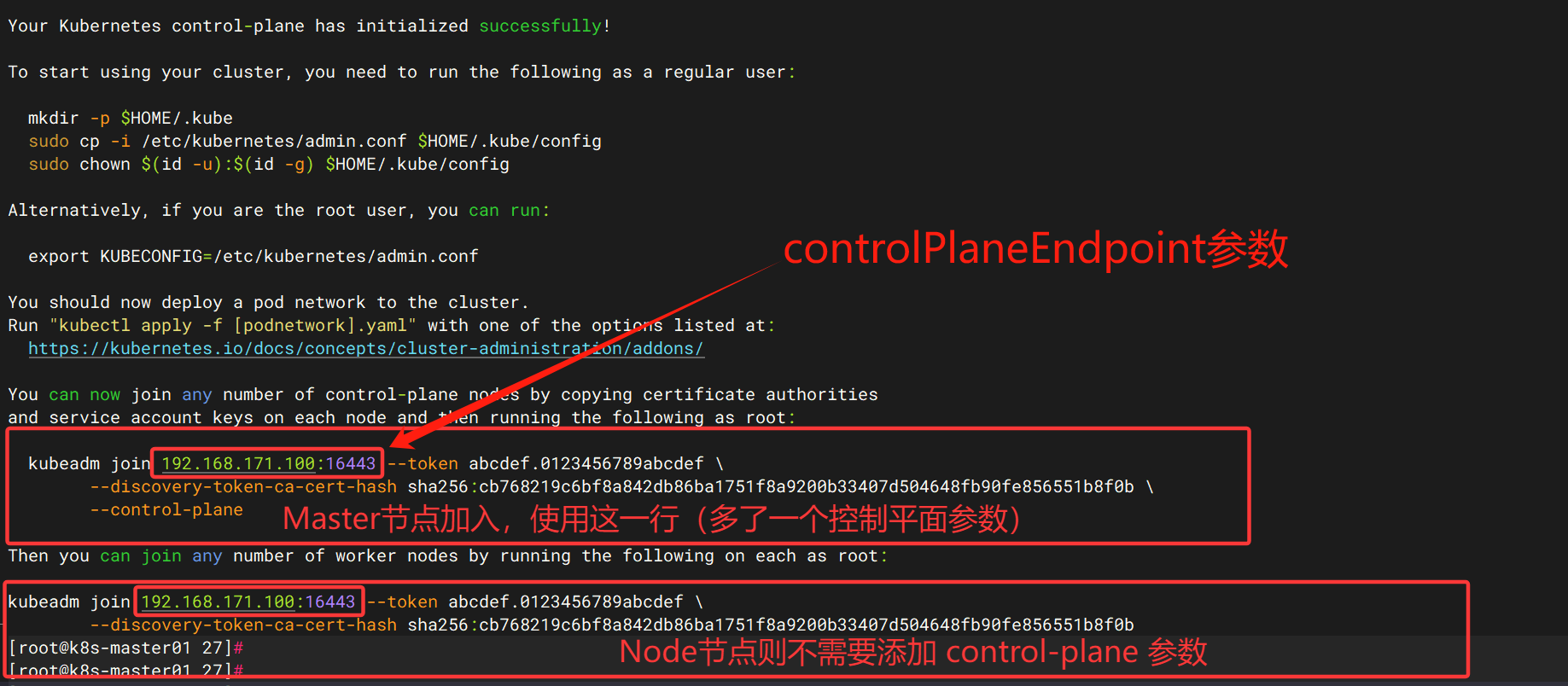
# 在 Master01 上
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeadm join 192.168.171.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:b31e3fd9ac1f7922133ab804c9eaab8eaf4737c5c3b013583c8a005021d1f3be \
--control-plane \
--cri-socket=unix:///var/run/cri-dockerd.sock
Master02、Master03:
主节点初始化时(
kubeadm init)生成唯一的根证书(CA),备用节点必须使用相同的 CA 证书,否则无法加入同一集群。重新生成证书会导致证书链不匹配,引发认证失败(如
x509: certificate is not valid for any names错误)。
mkdir -p /etc/kubernetes/pki/etcd
# admin.conf 文件
scp -r root@k8s-master01:/etc/kubernetes/admin.conf /etc/kubernetes/
# pki 目录下的核心证书
# 注意,不要一次性把目录拷贝过来,否则会覆盖自身的证书
scp root@k8s-master01:/etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} /etc/kubernetes/pki/
scp root@k8s-master01:/etc/kubernetes/pki/etcd/ca.* /etc/kubernetes/pki/etcd/加入集群:
kubeadm join 192.168.171.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cb768219c6bf8a842db86ba1751f8a9200b33407d504648fb90fe856551b8f0b \
--control-plane \
--cri-socket=unix:///var/run/cri-dockerd.sock mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Node:
kubeadm join 192.168.171.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cb768219c6bf8a842db86ba1751f8a9200b33407d504648fb90fe856551b8f0b \
--cri-socket=unix:///var/run/cri-dockerd.sock mkdir -p $HOME/.kube
scp -r root@k8s-master01:/etc/kubernetes/admin.conf /etc/kubernetes/
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config安装网络插件(Master01节点):
bash
# 下载 Calico 配置文件
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml
# 下载 Calico 配置文件
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml
# 修改 calico.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: calico-node
...
spec:
template:
spec:
containers:
- name: calico-node
env:
# 找到并修改这一行
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" # 与 kubeadm init 时指定的 podSubnet 一致,否则 Pod 间无法通信。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: calico-node
...
spec:
template:
spec:
containers:
- name: calico-node
env:
# 找到并修改这一行
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33" # 版本小于3.21,则需要修改为网卡名,大于 3.21 则没有此项 kubectl apply -f calico.yaml 测试:
# 定义 Deployment 资源
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment # Deployment 名称(建议与逻辑一致)
labels:
app: nginx
spec:
replicas: 1 # 副本数(默认 1)
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.17.5
ports:
- containerPort: 80 # 容器内服务端口(与 targetPort 一致)
---
# 定义 Service 资源(NodePort 类型)
apiVersion: v1
kind: Service
metadata:
name: nginx-service-nodeport
labels:
app: nginx
spec:
type: NodePort # 节点端口类型
ports:
- name: http
port: 8080 # 服务对外暴露端口
targetPort: 80 # 容器内目标端口
protocol: TCP # 协议(默认 TCP)
selector:
app: nginx # 匹配 Deployment 的 Pod 标签 [root@k8s-master01 27]# kubectl get service -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6h16m <none>
nginx-service-nodeport NodePort 10.104.208.100 <none> 8080:32041/TCP 17s app=nginx
[root@k8s-master01 27]# curl -I 10.104.208.100:8080 --connect-timeout 3
HTTP/1.1 200 OK
Server: nginx/1.17.5
Date: Fri, 09 May 2025 16:28:11 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 22 Oct 2019 14:30:00 GMT
Connection: keep-alive
ETag: "5daf1268-264"
Accept-Ranges: bytes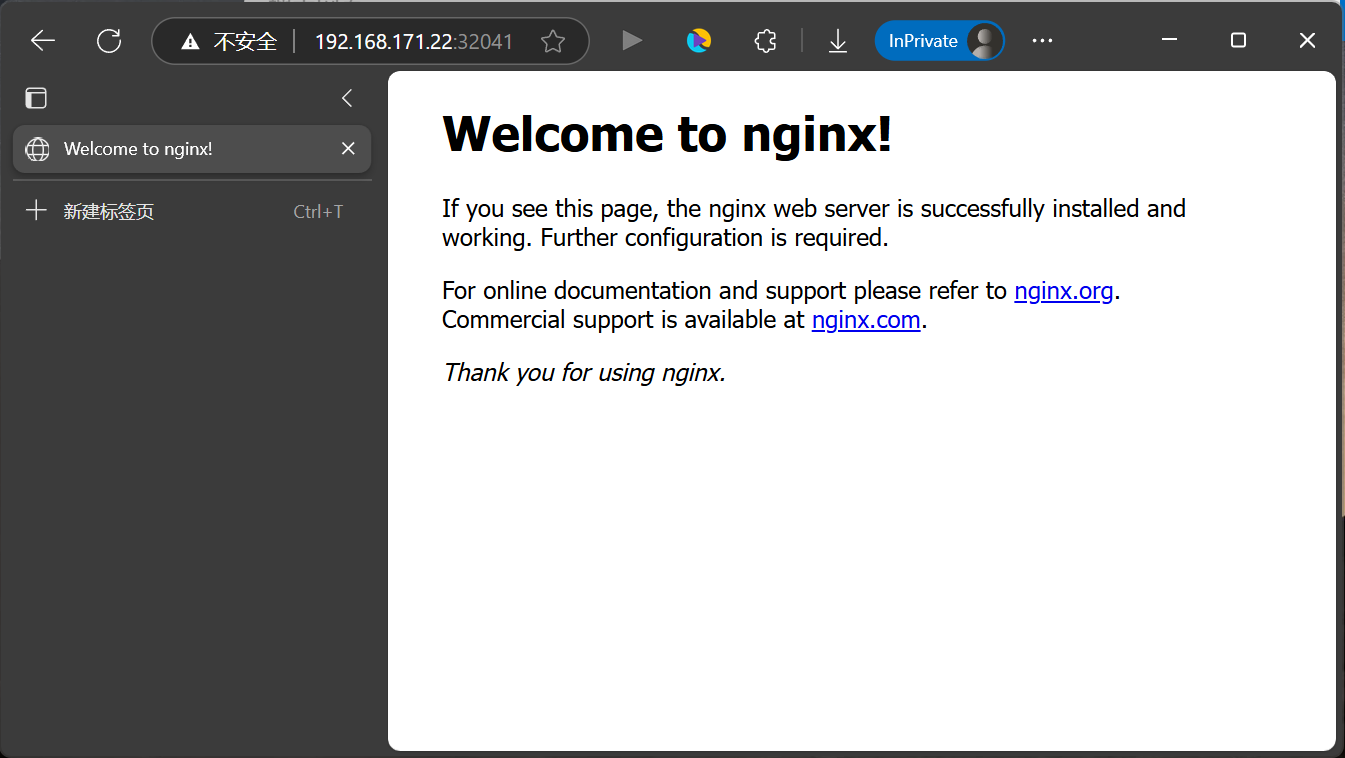
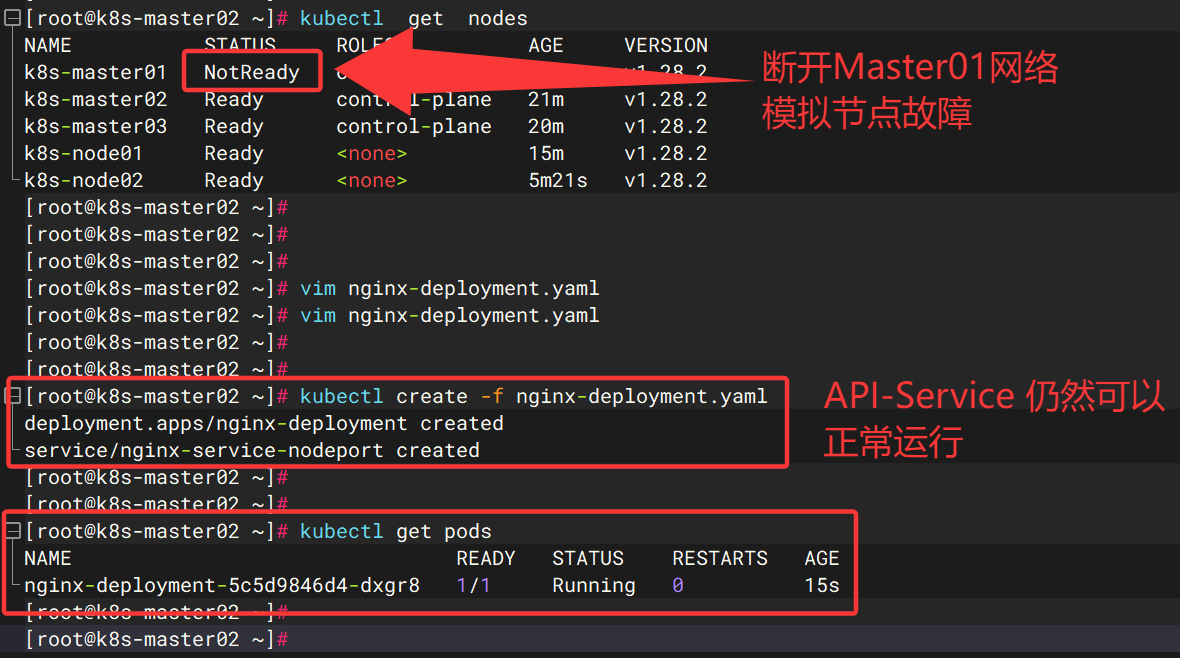
以下为调试内容:
kubectl apply -f calico.yaml # 安装需要时间,等待2分钟 # 创建 daemonset 测试节点 # cluster-install-test.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: cluster-install-test namespace: default labels: k8s-app: busybox spec: selector: matchLabels: k8s-app: busybox template: metadata: labels: k8s-app: busybox spec: containers: - name: busybox image: busybox:1.28 command: ["sh", "-c", "while true; do sleep 3600; done"] # 让容器持续运行 # 若节点有污点(如控制平面节点),添加以下容忍规则: tolerations: - key: "node-role.kubernetes.io/control-plane" operator: "Exists" effect: "NoSchedule" - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule"
# 添加污点容忍,在master02 则无法 ping baidu.com 暂时未找到原因 [root@k8s-master01 27]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cluster-install-test-5sj4r 1/1 Running 0 11s 10.244.122.129 k8s-master02 <none> <none> cluster-install-test-9brb4 1/1 Running 0 11s 10.244.85.193 k8s-node01 <none> <none> cluster-install-test-nmknh 1/1 Running 0 11s 10.244.135.130 k8s-node03 <none> <none> cluster-install-test-tgksv 1/1 Running 0 11s 10.244.58.193 k8s-node02 <none> <none> cluster-install-test-wzzh5 1/1 Running 0 11s 10.244.32.129 k8s-master01 <none> <none> [root@k8s-master01 27]# kubectl exec -it cluster-install-test-9brb4 -- sh / # ping baidu.com -c 2 PING baidu.com (172.29.0.5): 56 data bytes 64 bytes from 172.29.0.5: seq=0 ttl=127 time=0.421 ms 64 bytes from 172.29.0.5: seq=1 ttl=127 time=0.746 ms --- baidu.com ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.421/0.583/0.746 ms / # exit [root@k8s-master01 27]# kubectl exec -it cluster-install-test-5sj4r -- sh / # ping baidu.com -c 2 ping: bad address 'baidu.com' / # cat /etc/resolv.conf nameserver 10.96.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 / # exit # DNS 全被分配到 k8s-master02 # 豆包:从提供的 CoreDNS 部署配置来看,主要问题在于 Pod 反亲和性(podAntiAffinity)配置优先级不足 和 容忍规则不完整,导致 CoreDNS Pod 集中调度到单个节点。 [root@k8s-master01 27]# kubectl -n kube-system get pod -l k8s-app=kube-dns -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-5dd5756b68-2prgd 1/1 Running 0 3h9m 192.168.122.129 k8s-master02 <none> <none> coredns-5dd5756b68-rzrtv 1/1 Running 0 3h9m 192.168.122.131 k8s-master02 <none> <none>
