
括号中的 “常问”,指乐哥在面试过程中问过三次及以上的问题。
面试中的部分必会题,因频繁被问或过于简单,所以省略。
✅ Linux 系统相关
故障排查:
如何排查CPU使用率过高的问题(常问)
Java程序排查:linux cpu飙高原因排查(有手就行)_linux cpu故障注入报告-CSDN博客
第1步,使用
top命令找到占用CPU高的进程。第2步,使用
ps –mp命令找到进程下占用CPU高的线程ID。第3步,使用
printf命令将线程ID转换成十六进制数。第4步,使用
jstack命令输出线程运行状态的日志信息。
使用
perf命令:Linux系统CPU持续彪高,如何排查?哔哩哔哩bilibili
perf 是 Linux 性能分析工具,用于性能调优、诊断、分析和跟踪。
如果只想监控某个特定进程,可以使用 -p 参数:
perf top -p <pid>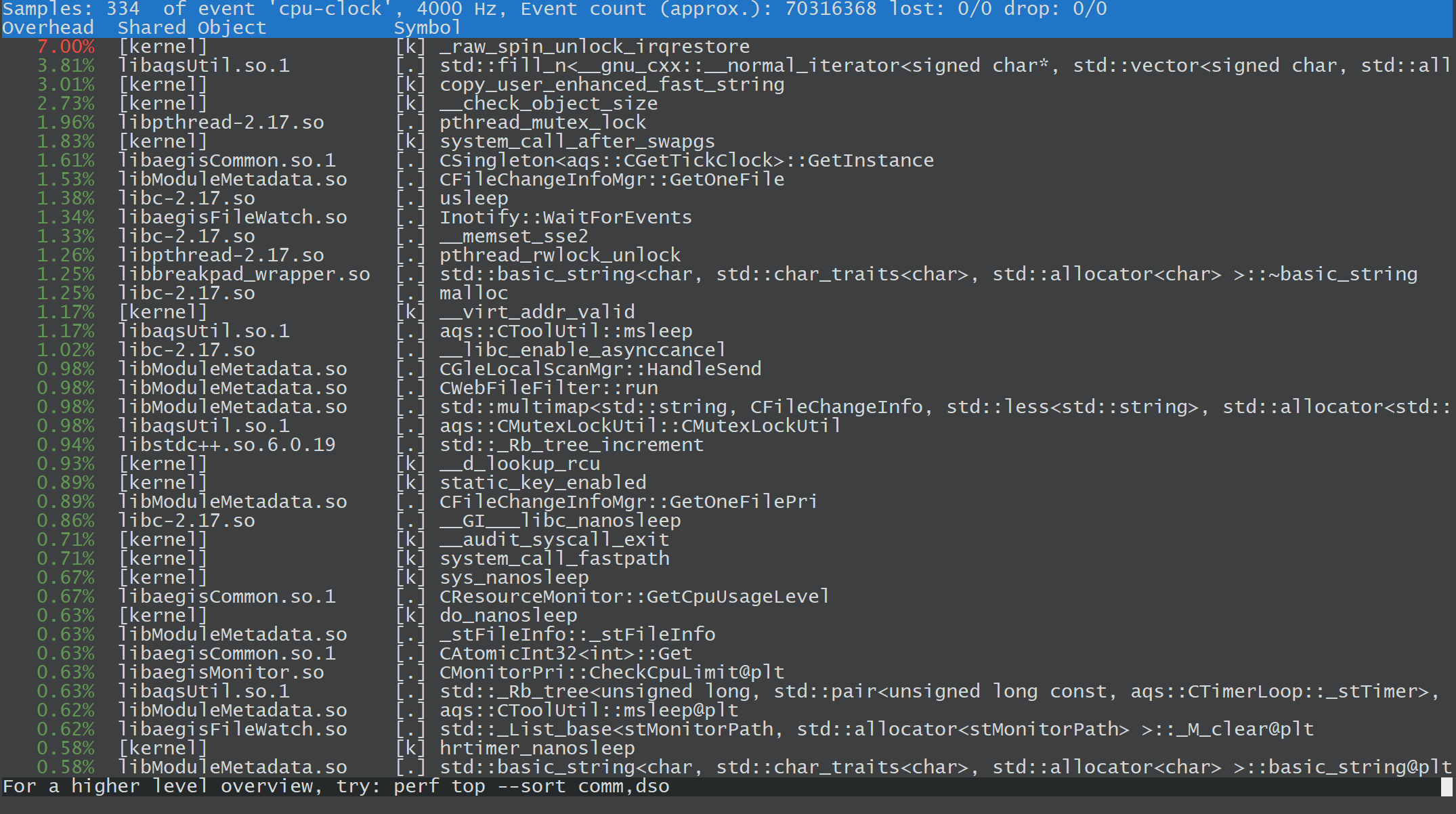
Overhead (开销百分比): 图中:
8.70%表示_raw_spin_unlock_irqrestore函数占用了 8.7% 的 CPU 时间。在性能分析中,这个值表明该函数消耗的 CPU 比例,越高越重要,通常需要优化。Shared Object (共享对象): 图中:
[kernel]或libc-2.17.so。这列显示了函数所在的共享对象(库)或内核模块。[kernel]表示这是内核中的函数,libc-2.17.so表示该函数在 GNU C 库中。Symbol (符号): 图中:
_raw_spin_unlock_irqrestore或__memset_sse2。这是调用栈中的函数名称。它表示消耗 CPU 时间的具体函数或符号。
如何查找和处理僵尸进程?
僵尸进程的产生:
子进程执行完成:当子进程完成它的任务并退出时,操作系统会为其保留一些信息(如退出状态),以便父进程可以调用
wait()来获取这些信息。父进程未回收状态:如果父进程没有调用
wait()来回收子进程的退出状态,那么子进程就会处于僵尸状态,直到父进程回收它。父进程退出:如果父进程终止,操作系统会将僵尸进程的父进程 ID 设为 1,即由
init进程来回收这个子进程。
僵尸进程本身并不执行任何代码,也不会占用CPU时间。但是,它们会占用一定的系统资源,包括进程表中的一个条目以及与之相关的其他数据结构。因此,如果系统中存在大量的僵尸进程,就可能会导致系统资源的浪费和性能下降。
查找和处理僵尸进程:
使用
ps命令:ps aux | grep 'Z'或者使用:
ps -ef | grep 'Z'其中,
Z表示进程处于僵尸状态。使用
top命令: 通过STAT列显示进程的状态。僵尸进程的状态会显示为Z。 在top界面中,可以按下Z键来高亮显示僵尸进程(如果有的话)。 或者直接过滤出僵尸进程:top -n 1 | grep 'Z'使用
htop命令: 僵尸进程会显示为红色或带有Z状态的进程。
ECS频繁重启要怎么排查
检查系统日志:
查看
/var/log/messages和/var/log/syslog: 通常包含系统级别的日志信息,可能包括内核崩溃、OOM(内存溢出)等问题。# 查看系统日志 cat /var/log/messages | grep -i 'reboot' cat /var/log/syslog | grep -i 'reboot'查看
/var/log/dmesg:dmesg命令打印内核环形缓冲区的消息,常用于排查硬件、驱动、内核崩溃等问题。dmesg | tail -n 50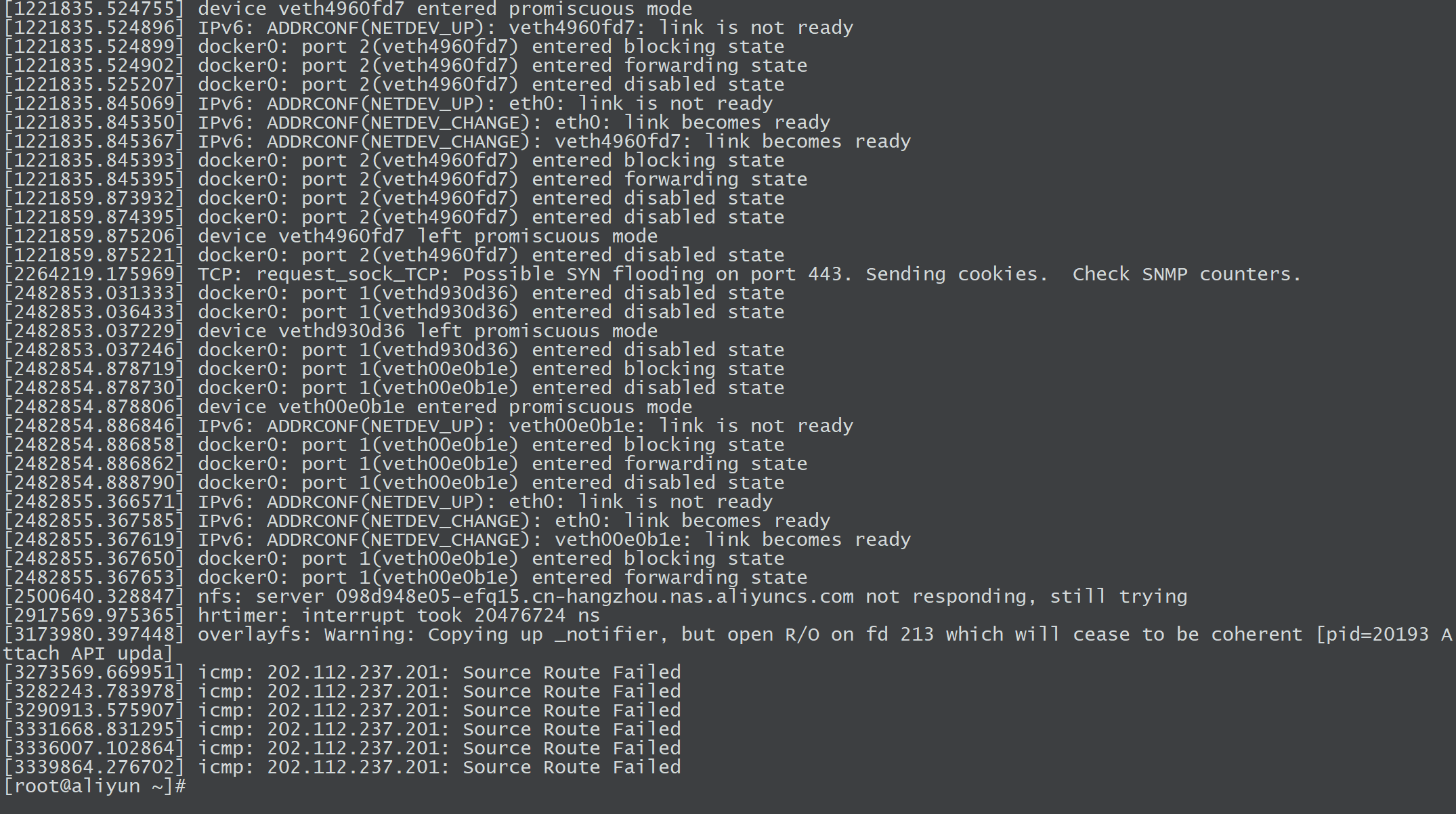
逐一分析这些
dmesg日志,这些信息直接反映了系统内核、网络、存储等层面的运行状态和潜在问题:括号中的
[2482855.367650]是 Linux 内核日志的时间戳,格式为[秒.微秒],可以使用dmesg -T直接显示人类可读时间。Docker 网络状态变化
[2482855.367650] docker0: port 1(veth00e0b1e) entered blocking state [2482855.367653] docker0: port 1(veth00e0b1e) entered forwarding state # docker0 是 Docker 默认的 Linux 桥接网络接口。 # veth00e0b1e 是一个虚拟网卡(一端在容器内,另一端连接到 docker0 桥)。 # blocking state:端口暂时停止转发数据(可能是在等待网络配置就绪)。 # forwarding state:端口开始转发数据(容器网络已就绪,可以正常通信)。通常出现在容器启动、重启或网络重新配置时。
如果频繁出现,可能意味着容器频繁启停,需要检查容器健康状况或编排策略(如 Kubernetes 重启策略)。
NFS 服务器响应超时
[2500640.328847] nfs: server 098d948e05-efq15.cn-hangzhou.nas.aliyuncs.com not responding, still trying # 系统挂载了阿里云 NAS(NFS 协议),但客户端在规定时间内未收到 NAS 服务器的响应。 # 内核会持续重试,但此时依赖 NFS 的应用可能会出现卡顿或 I/O 超时。 # 其实这里乐哥将后端的 NFS 给删除了,所以报错。可能原因:
网络抖动或延迟(阿里云 NAS 与 ECS 不在同一可用区、带宽饱和、TCP 连接丢包)。
NAS 服务器负载过高或临时故障(可在阿里云控制台查看 NAS 监控)。
客户端 NFS 挂载参数不合理(如
timeo超时时间过短)。防火墙或安全组限制了 NFS 端口(111、2049)。
高精度定时器中断耗时过长
[2917569.975365] hrtimer: interrupt took 20476724 ns # hrtimer(High-Resolution Timer)是 Linux 高精度定时器,用于需要精确时间控制的场景(如多媒体、实时任务)。 # 该日志表示一次定时器中断耗时 20.47 毫秒(正常应在微秒级),属于严重超时。可能原因:
CPU 负载过高(如进程占用 100% CPU),导致定时器中断无法及时处理。
系统存在 I/O 瓶颈(如磁盘读写繁忙、NFS 延迟),引发 CPU 等待。
硬件问题(如 CPU 过热、内存故障)。
内核版本或驱动兼容性问题。
排查方向:
# 查看 CPU 负载和进程状态 top mpstat -P ALL 1 # 检查磁盘 I/O iostat -x 1 # 查看内存使用 free -hOverlayFS 存储驱动警告
[3173980.397448] overlayfs: Warning: Copying up _notifier, but open R/O on fd 213 which will cease to be coherent [pid=20193 Attach API upda] # overlayfs 是 Docker 默认的存储驱动,采用分层文件系统(镜像层 + 容器可写层)。 # 该警告表示:容器在尝试修改一个只读层(R/O)中的文件(_notifier)时,需要将文件复制到可写层(copy up 操作),但复制过程中文件描述符(fd 213)已变为只读,可能导致数据一致性问题。可能原因:
容器镜像本身存在权限问题(如关键文件被设为只读)。
容器内进程异常操作只读文件(如尝试修改系统配置文件)。
OverlayFS 驱动版本不兼容或配置不当。
影响:
可能导致容器内文件修改失败、数据丢失或应用异常。
排查方向:
# 查看容器挂载的 overlayfs 层 docker inspect <container_id> | grep -i "overlay" # 检查容器内文件权限 docker exec -it <container_id> ls -l /path/to/_notifierICMP 源路由失败
[3273569.669951] icmp: 202.112.237.201: Source Route Failed # icmp 是 Internet Control Message Protocol,用于网络错误报告和诊断。 # Source Route Failed 表示:系统尝试通过 源路由(由发送方指定数据包传输路径)访问 202.112.237.201,但该路径无效或被中间设备(如路由器、防火墙)拒绝。可能原因:
目标 IP(202.112.237.201)不支持源路由,或源路由选项被禁用。
网络中间设备(如防火墙、阿里云安全组)拦截了带源路由的 ICMP 数据包。
系统存在恶意扫描或异常网络请求(源路由可被用于绕过网络限制)。
排查方向:
# 测试目标 IP 连通性 ping 202.112.237.201 # 查看系统路由表 route -n # 检查防火墙规则 iptables -L -n
查看
journalctl(对于使用systemd的系统):journalctl -xe
检查内存和资源使用情况:
检查内存使用情况:如果系统因内存溢出(OOM) 而导致重启,可以通过查看
dmesg或日志文件中与内存相关的警告来确认。dmesg | grep -i 'out of memory'监控 CPU 和内存使用:使用
top、htop、free等工具查看系统的实时资源消耗情况。top free -m检查磁盘使用情况:磁盘空间满了也会导致系统出现异常,使用
df和du命令检查磁盘空间:df -h du -sh /path/to/directory
检查云平台事件日志: 如果是阿里云ECS实例的重启,可以查看阿里云控制台中的 “云监控” 和 “事件” 日志,了解是否有云平台的操作导致了实例重启。
登录到阿里云控制台,进入 云监控 -> 事件日志,检查是否有因为资源不足、配置更改或其他操作导致的实例重启记录。
在 云监控 中查看实例的 CPU、内存、磁盘、网络 等资源使用情况,看看是否有异常波动。
检查阿里云硬件故障: 如果 ECS 实例频繁重启,可能与物理硬件问题有关。阿里云提供了硬件健康检查,可以通过 阿里云控制台 查询是否存在硬件故障:
登录到阿里云控制台,查看 ECS实例的硬件健康 状况。
如果存在硬件故障,可以联系阿里云客服,进行实例迁移或硬件更换。
检查是否存在恶意软件或错误配置: 恶意软件、资源竞争或配置错误可能会导致实例出现不稳定,检查以下内容:
检查是否有恶意软件:运行杀毒软件或使用
chkrootkit、rkhunter等工具扫描是否有rootkit或其他恶意程序。chkrootkit rkhunter --check检查实例配置:检查实例的内核参数、服务配置和启动项是否合理,是否有进程异常导致资源争抢。
检查定时任务和自动化脚本: 如果 ECS 实例中有定时任务(如 cron 任务) 或自动化脚本(如使用 Ansible、SaltStack 等配置管理工具),这些任务也有可能导致实例重启。检查是否存在错误配置的定时任务或脚本。
查看
cron日志:cat /var/log/cron查看系统中是否有执行自动化脚本的历史记录。
机器装java运行不了,是什么原因?
环境变量问题(最常见)
现象:
java: command not found原因:Java 已安装,但环境变量
PATH或JAVA_HOME未配置;或/etc/profile、~/.bashrc未生效。排查:
echo $JAVA_HOME echo $PATH | grep java解决:
export JAVA_HOME=/usr/local/java/jdk1.8.0_361 export PATH=$JAVA_HOME/bin:$PATH source /etc/profile
安装路径或版本错误
现象:
-bash: /usr/bin/java: No such file or directory原因:JDK 未正确安装(
rpm包未解压、软链接错误);多版本 JDK 共存时优先级混乱。排查:
ls -l /usr/bin/java update-alternatives --display java解决:
sudo update-alternatives --config java
JRE/JDK 不匹配
现象:
Unsupported major.minor version 52.0原因:程序编译使用了更高版本 JDK(如
JDK11),运行环境是低版本(如JRE8)。解决:升级运行环境或重新编译为低版本兼容。
权限或 SELinux 限制
现象:
Permission denied原因:Java 可执行文件无执行权限;或
SELinux拒绝执行外部二进制。排查:
ls -l $JAVA_HOME/bin/java getenforce解决:
chmod +x $JAVA_HOME/bin/java setenforce 0 # 临时关闭SELinux验证
系统架构或依赖缺失
现象:
bash: ./java: cannot execute binary file: Exec format error原因:安装了错误架构版本(比如在
ARM上装了x86JDK);缺少依赖库(glibc等)。排查:
file $(which java) uname -m确保架构匹配,如
x86_64对应 64位系统。
✅ 进程/线程
进程和线程的主要区别是什么?
进程是资源独立的执行单位,线程是进程中的轻量级执行单位,线程间共享进程资源。
kill -9和kill -15命令有什么区别?
✅ Linux命令
du和df命令显示结果不一致的原因是什么?
df 和 du 结果不一致的原因主要是它们计算磁盘空间的方式不同。
df -h(Disk Free):基于文件系统的元数据统计,直接读取文件系统的 “已用块数” 和 “可用块数”,反映的是文件系统整体的空间占用情况。du -sh(Disk Usage):基于遍历目录下的文件和子目录,累加每个文件的实际大小,统计的是目录内所有文件的 “逻辑大小” 总和。
# 使用 df 查看根文件系统的空间情况
[root@aliyun ~]# df -h /
文件系统 容量 已用 可用 已用% 挂载点
/dev/vda1 40G 4.9G 33G 13% /
# 使用 du 查看根目录的空间情况
[root@aliyun ~]# du -sh /
du: 无法访问"/proc/3624/task/3624/fd/3": 没有那个文件或目录
du: 无法访问"/proc/3624/task/3624/fdinfo/3": 没有那个文件或目录
du: 无法访问"/proc/3624/fd/4": 没有那个文件或目录
du: 无法访问"/proc/3624/fdinfo/4": 没有那个文件或目录
5.3G /
[root@aliyun ~]# 在这个例子中:
df显示的是根文件系统的整体空间使用情况,其中包括了文件系统元数据、缓存、以及已删除但未回收的文件空间。du显示的是根目录下实际文件和目录的空间使用情况,不包括元数据和缓存等。
Linux目录结构和作用
Linux 系统目录结构 | 菜鸟教程
如何查看Linux系统信息(版本信息、内核信息等)
查看系统版本信息:
查看内核信息:
其他常用系统信息命令:
如何设置环境变量
主要分 临时生效 和 永久生效 两类,具体方式取决于变量的作用范围(全局 / 用户 / 会话)。
会话级临时设置(
export命令)直接通过
export命令定义变量,无需修改配置文件,直接生效。export 变量名=变量值 # 等号前后无空格,值含空格需用引号包裹关闭当前终端 / SSH 会话后,变量会丢失。
若需临时取消变量:
unset 变量名。
用户级永久设置
修改当前用户的 bash 配置文件,每次用户登录时自动加载变量。
~/.bashrc:用户每次打开终端(包括非登录会话)都会加载(推荐)。~/.bash_profile:仅用户登录时加载(部分系统默认不启用,需手动创建)。
系统级永久设置
修改系统公共配置文件,所有用户登录后都会加载,适合部署全局工具(如 Nginx、MySQL 等服务的环境变量)。
选择配置文件(二选一,优先
/etc/profile):/etc/profile:系统全局环境变量配置,所有用户(bash 终端)都会加载。/etc/environment:系统级环境变量文件,语法更简单(无需export),但部分老系统不支持。
LVM扩容的具体流程
LVM 扩容的整体思路: LVM 扩容分为三步:1️⃣ 扩物理卷(PV) → 2️⃣ 扩卷组(VG) → 3️⃣ 扩逻辑卷(LV) 并扩文件系统 先
pvcreate创建物理卷,再vgextend扩展卷组,最后lvextend+xfs_growfs扩展文件系统。
详细:LVM 逻辑卷管理 - 乐可夫斯基的博客
rpm命令如何查看安装日期?(偏门问题)
先来了解一下 rpm -q 这个参数:
rpm -q 是 RPM 包管理系统中用于 查询(Query) 已安装软件包信息的核心命令。q 是 query 的缩写。
它的基本语法是:
rpm -q [选项] <包名>最基础用法:查询指定包是否安装
rpm -q nginx作用:检查
nginx这个包是否已经安装在系统上。输出结果:
如果已安装,会显示完整的包名和版本,例如:
nginx-1.20.1-9.el8.x86_64。
如果未安装,会提示:
package nginx is not installed。
常用查询选项(组合使用)
-a:所有包-i:详细信息-l:列出文件-c:配置文件-d:文档文件-R:依赖关系-f:通过文件反向查包
通过
rpm -q结合查询格式(--queryformat)或详细信息(-i)选项,直接提取安装时间字段。# 查询已安装的 nginx 包的详细信息 rpm -qi nginx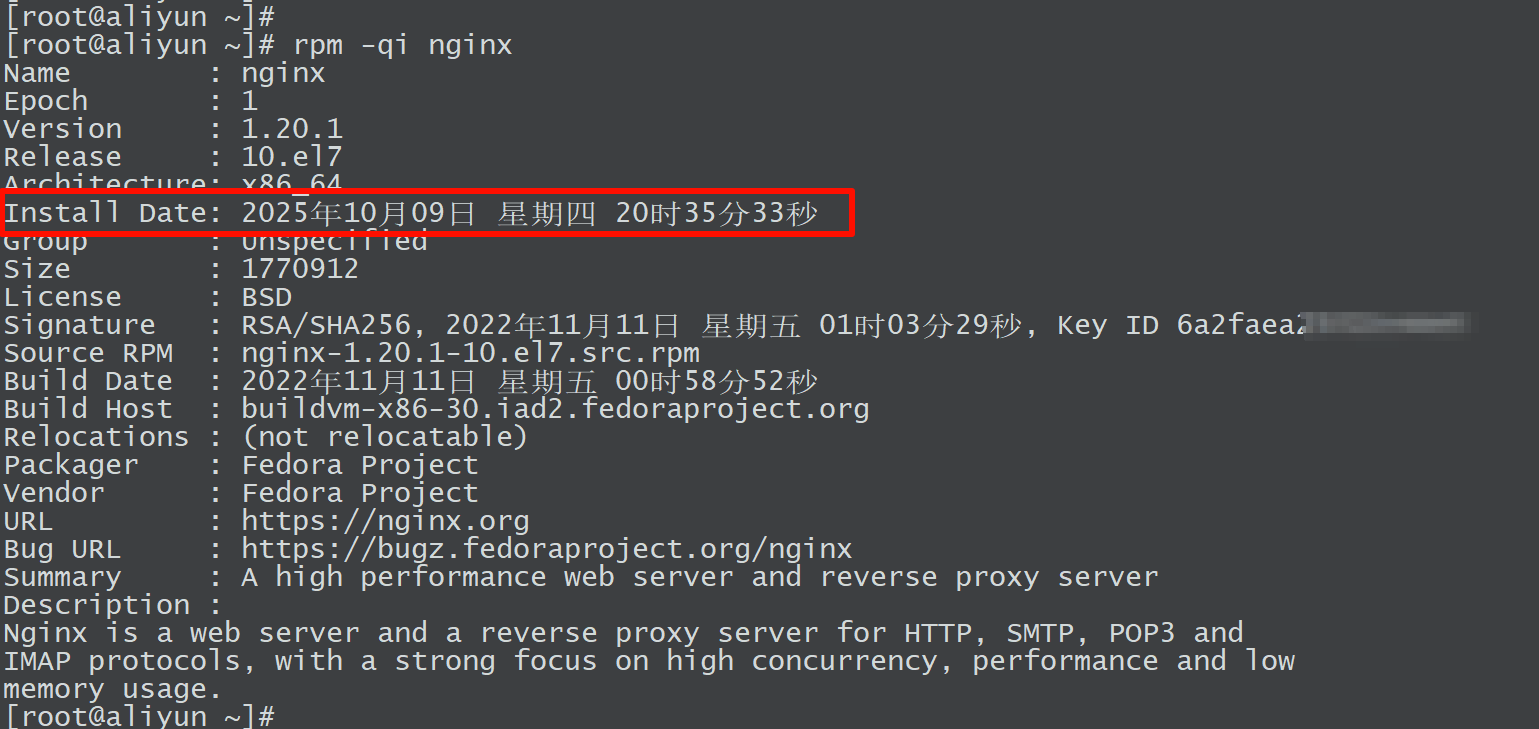
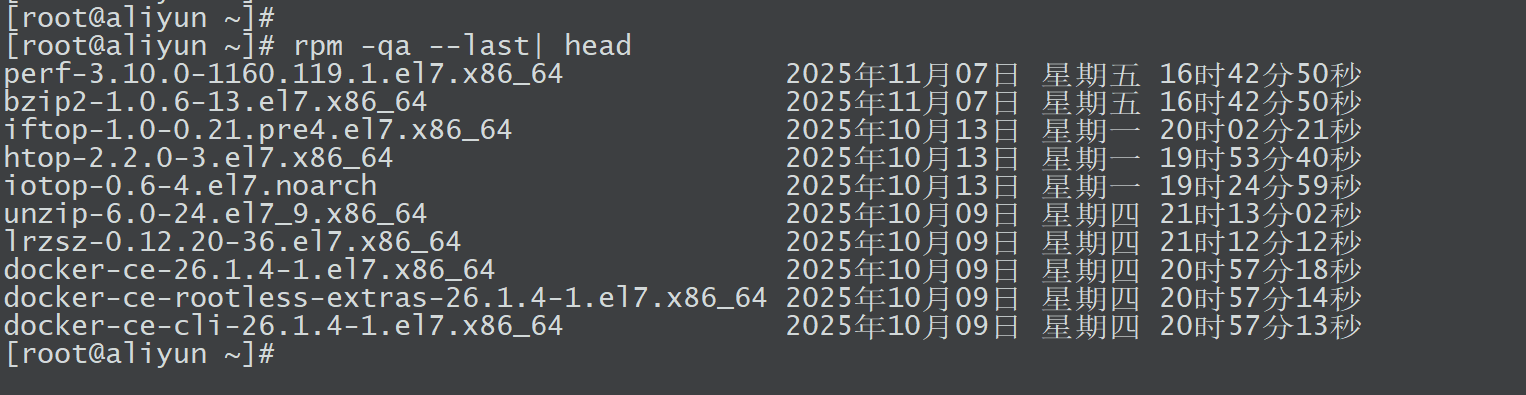
使用
rpm -qa --last参数用于按安装时间倒序列出所有已安装的包
✅ 中间件
Nginx
Nginx如何获取真实客户端IP?
情形1:客户端 -> Nginx -> Django 此时 Nginx 与客户端直接建立连接,$remote_addr变量默认就是 “客户端真实 IP”(因为没有中间代理)。
http {
server {
listen 80;
location / {
# 1. 给Django传递“客户端真实IP”(单IP)
proxy_set_header X-Real-IP $remote_addr;
# 2. 给Django传递完整的代理链(此时只有客户端IP,因为无其他代理)
proxy_set_header X-Forwarded-For $remote_addr;
# 3. 传递原始请求的主机名(确保Django识别正确的域名)
proxy_set_header Host $host;
# 转发请求到Django
proxy_pass http://127.0.0.1:8000;
}
}
}情形2:客户端 -> Nginx1 -> Nginx2 -> Django 问题:多层代理下,Nginx2 和 Django 如何穿透代理链拿到真实 IP?
此时客户端先连接 Nginx1,再转发到 Nginx2,最后到 Django。默认情况下:
Nginx2 看到的
$remote_addr是 “Nginx1 的 IP”(而非客户端 IP);Django 看到的
$remote_addr是 “Nginx2 的 IP”(而非客户端 IP)。
必须通过配置让 IP 链在代理间传递,并让后端解析出最原始的客户端 IP。
第一步:Nginx1(第一层代理,对接客户端)配置
server {
listen 80;
location / {
# 1. 给Nginx2传递“客户端真实IP”(此时Nginx1的$remote_addr是客户端IP)
proxy_set_header X-Real-IP $remote_addr;
# 2. 给Nginx2传递完整代理链:客户端IP + Nginx1的IP(用$proxy_add_x_forwarded_for自动拼接)
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_pass http://nginx2_backend; # 转发给Nginx2
}
}$proxy_add_x_forwarded_for的作用是 “将当前$remote_addr(客户端 IP)拼接到原有X-Forwarded-For头后面”。若客户端未发送该头,则结果为客户端IP;若有,则为原有IP链, 客户端IP。
这一步是为了让 “客户端 IP” 进入代理链,否则 Nginx2 永远不知道真实客户端是谁。
第二步:Nginx2(第二层代理,对接 Nginx1)配置
http {
# 1. 告诉Nginx2:从X-Forwarded-For头中解析真实IP
real_ip_header X-Forwarded-For;
# 2. 告诉Nginx2:信任Nginx1的IP(只有来自Nginx1的请求才解析,防止伪造IP)
set_real_ip_from <Nginx1的IP或网段>; # 例如 192.168.1.100/32
# 3. 递归解析:从IP链中去掉所有“信任的代理IP”,剩下的第一个就是客户端真实IP
real_ip_recursive on;
server {
listen 80;
location / {
# 1. 给Django传递解析后的真实IP($realip_remote_addr是real_ip模块处理后的结果)
proxy_set_header X-Real-IP $realip_remote_addr;
# 2. 给Django传递完整代理链:客户端IP, Nginx1IP(Nginx2自动拼接自己的IP)
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_pass http://127.0.0.1:8000; # 转发给Django
}
}
}real_ip模块的作用是 “从代理头中解析真实 IP,修改 Nginx 内部的$remote_addr”。
X-Real-IP与X-Forwarded-For的区别:
X-Real-IP:简化的真实 IP(仅客户端 IP),适合后端快速获取真实来源;X-Forwarded-For:完整的代理链(格式:客户端IP, 代理1IP, 代理2IP...),此时只有客户端 IP,方便后端知道 “请求是否经过代理”。
Nginx做过哪些优化(常问)
回答要体现出你能从多个维度优化:系统层、Nginx配置层、业务层、缓存层。
系统层优化(操作系统级):
文件句柄数:
ulimit -n 65535防止高并发下连接被限制。
内核参数优化(
/etc/sysctl.conf):net.core.somaxconn = 65535 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.ip_local_port_range = 1024 65000 net.ipv4.tcp_tw_reuse = 1作用:提升 TCP 并发能力、端口复用能力。
使用
epoll模型(Linux 默认支持):高并发连接场景下,异步非阻塞I/O模型性能更好。
Nginx 配置层优化:
worker 进程调优:
worker_processes auto; worker_connections 65535;一个 worker 支持的最大连接数 ≈
worker_connections×worker_processes。开启多路复用(
HTTP/2):减少握手和连接数。使用
sendfile、tcp_nopush、tcp_nodelay:sendfile on; tcp_nopush on; tcp_nodelay on;→ 减少用户态与内核态的切换,提高数据发送效率。
开启
gzip压缩:gzip on; gzip_types text/plain text/css application/json;→ 减少带宽占用。
缓存与静态资源优化:
浏览器缓存:
location /static/ { expires 7d; add_header Cache-Control "public"; }Nginx 缓存:
proxy_cache:缓存上游响应,减轻后端压力。fastcgi_cache:动态页面缓存(如PHP、Python)。
CDN/负载均衡结合:
在公网场景可前置
CDN;内网可通过 Nginx
upstream实现反向代理负载均衡。
日志与监控优化:
日志分级与异步写入:关闭不必要的
access log或使用syslog异步收集。监控接入
Prometheus: 通过nginx-vts-exporter或nginx-exporter采集指标: QPS、响应时延、4xx/5xx 比例、连接状态等。
✅ 数据库
MySQL
你们公司MySQL的备份策略是什么(常问)
以乐哥做的最近的项目为例:
全量备份:每 7 天执行 1 次(默认每周二 00:00,业务低峰期),生成完整数据快照,作为增量备份的基础。
增量备份:每天执行 1 次(默认每天 02:30),仅备份上一次全量 / 增量备份后变化的数据,减少备份耗时和存储占用。
备份工具:
Percona XtraBackup(支持热备,不阻塞InnoDB业务读写,备份效率高)。数据安全性:备份文件本地存储 + 异地同步(可选),备份日志记录,过期自动清理。
# 全量备份
xtrabackup --user=root --password=密码 --backup --target-dir=/backup/full_20250806
# 基于全量的增量备份(仅备份变化的数据页)
xtrabackup --user=root --password=密码 --backup --target-dir=/backup/incr_20250806 \
--incremental-basedir=/backup/full_20250806根据实际业务回答即可。
补充:基于时间点恢复
找到误操作时间点(如2025-08-06 10:30:00执行了
DROP TABLE);恢复最近的全量备份(如2025-08-06 00:00的备份);
解析
binlog,应用从备份完成时间到误操作前的日志:# 导出binlog中2025-08-06 00:00:00到10:29:59的操作 mysqlbinlog --start-datetime="2025-08-06 00:00:00" \ --stop-datetime="2025-08-06 10:29:59" \ /var/lib/mysql/binlog.000005 | mysql -u root -p'密码'
MySQL备份脚本的关键点有哪些?
我不知道为什么面试官会问这种题目。
#!/bin/bash
# 作者:不断精进,终生成长
# 功能:MySQL安全备份系统
# ------------------ 配置中心 ------------------
DB_USER="backup" # 备份专用账户
DB_PASS="123" # 备份账户密码
DB_PORT="3307" # 备份账户的端口
DB_HOST="10.0.0.201" # 数据库地址
BACKUP_ROOT="/data/mysql_backup" # 备份存储目录
RETAIN_DAYS=14 # 备份保留周期
LOG_DIR="/var/log/mysql_backup" # 审计日志目录
# ------------------ 初始化模块 ------------------
function init_env() {
local timestamp=$(date "+%Y%m%d-%H%M%S")
export BACKUP_DIR="${BACKUP_ROOT}/$(date +%Y%m%d)"
mkdir -p "${BACKUP_DIR}" "${LOG_DIR}"
LOG_FILE="${LOG_DIR}/backup_${timestamp}.log"
exec 3>&1 4>&2 # 备份标准输出/错误描述符
exec > >(tee -a "${LOG_FILE}") 2>&1
}
# ------------------ 备份执行模块 ------------------
function perform_backup() {
local backup_file="${BACKUP_DIR}/full_${timestamp}.sql.gz"
echo "[$(date +'%T')] 阶段1:启动全量备份..."
mysqldump -h ${DB_HOST} -u ${DB_USER} -p${DB_PASS} -P${DB_PORT} \
--single-transaction \
--routines \
--events \
--triggers \
--all-databases 2>/dev/null | gzip > "${backup_file}"
local ret_code=$?
if [[ ${ret_code} -eq 0 ]]; then
echo "[$(date +'%T')] 备份成功 | 文件: ${backup_file} 大小: $(du -sh ${backup_file} | cut -f1)"
else
echo "[$(date +'%T')] 错误:备份失败!错误码: ${ret_code}"
exit 1
fi
}
# ------------------ 清理模块 ------------------
function purge_backups() {
echo "[$(date +'%T')] 阶段2:清理过期备份..."
find "${BACKUP_ROOT}" -type f -name "*.sql.gz" \
-mtime +${RETAIN_DAYS} \
-exec rm -fv {} \; | tee -a "${LOG_FILE}"
}
# ------------------ 主流程 ------------------
main() {
timestamp=$(date "+%Y%m%d-%H%M%S")
init_env
echo "================ 备份启动 [${timestamp}] ================"
perform_backup
purge_backups
echo "================ 备份完成 [耗时: ${SECONDS}s] ================"
exec 1>&3 2>&4 # 恢复标准输出/错误
}
mainMySQL主从复制原理(常问)
必会,略。
MySQL主从不同步怎么办?
检查主从复制状态: 在从库上运行:
SHOW SLAVE STATUS\G查看
Slave_IO_Running和Slave_SQL_Running的状态:如果这两个状态都是
Yes,说明复制正常。如果不是,继续排查。注意
Last_IO_Error和Last_SQL_Error,它们会显示具体的错误信息。
查看错误日志: 检查从库的错误日志和主库的错误日志,可能会有关于复制失败的更多信息。
检查主库 binlog 设置: 确保主库的
binlog被启用,并且expire_logs_days或max_binlog_size没有过早地删除了必要的日志。 在主库上运行:SHOW VARIABLES LIKE 'log_bin'; SHOW VARIABLES LIKE 'expire_logs_days';检查主从数据库版本一致性: 确保主库和从库的 MySQL 版本兼容,有时版本差异可能会导致复制问题。
检查网络延迟或中断: 如果网络不稳定,可能导致从库无法及时接收到主库的
binlog,导致复制延迟。重新启动复制: 如果出现 IO 错误或其他问题,尝试停止并重新启动复制进程:
STOP SLAVE; START SLAVE;确保
Master_Log_File和Read_Master_Log_Pos是正确的。使用mysqlbinlog查看日志: 如果有 SQL 错误,可能是某些事务无法在从库上执行。使用
mysqlbinlog查看主库的binlog,并手动定位并解决有问题的 SQL 语句。主从数据不一致时的解决方案: 如果主从数据不一致,可以通过以下方式解决:
使用
pt-table-checksum检查数据差异,并通过pt-table-sync修复。如果使用
GTID模式,使用SET GLOBAL enforce-gtid-consistency = ON;强制一致性。
重新设置复制: 如果以上方法都无效,可以考虑重新配置复制:
在主库上创建新的复制账户和复制文件:
FLUSH TABLES WITH READ LOCK; SHOW MASTER STATUS;记录
Master_Log_File和Master_Log_Pos,在从库上重新配置。在从库上执行:
CHANGE MASTER TO MASTER_HOST='主库IP', MASTER_USER='复制账号', MASTER_PASSWORD='密码', MASTER_LOG_FILE='log-bin文件名', MASTER_LOG_POS=日志位置; START SLAVE;
MySQL场景题:银行生产环境下,MySQL 主从架构因主库写入量大导致同步慢,需在不做大架构改动(不分库分表、不临时加中间件)、最小代价前提下优化。
优先释放从库 SQL 线程能力(并行复制)→ 减小主库 binlog 生成 / 传输压力 → 微调从库资源 → 优化同步 / 网络机制
第一步:先定位同步慢的核心瓶颈(避免盲目优化)
优化前必须精准定位瓶颈点,通过以下命令分析:
-- 从库执行,核心关注字段
SHOW SLAVE STATUS\G关键字段解读:
同时补充监控:
主库:binlog 生成速度、磁盘 IO 利用率、网络出口带宽;
从库:CPU 利用率(SQL 线程重放耗 CPU)、磁盘 IO(innodb 刷盘)、内存命中率;
主从网络:延迟(ping)、带宽利用率(binlog 传输占比)。
第二步:分维度最小代价优化方案
维度 1:从库 SQL 线程并行复制(核心优化,0 架构改动)
主库高写入时,从库单 SQL 线程重放是最常见瓶颈,启用并行复制是性价比最高的优化(MySQL 5.6 + 支持,5.7 + 更完善)。
1. MySQL 5.7+
-- 从库临时生效(生产建议先临时改,验证后写入my.cnf)
STOP SLAVE;
-- 开启并行复制,线程数按CPU核数调整(如8核设为6-8,避免超线程)
SET GLOBAL slave_parallel_workers = 8;
-- 基于逻辑时钟的并行复制(按事务提交顺序并行,保障一致性,适配银行场景)
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK';
-- 保障事务提交顺序(避免数据不一致,银行必开)
SET GLOBAL slave_preserve_commit_order = 1;
-- 关闭事务重试(避免异常)
SET GLOBAL slave_transaction_retries = 10;
START SLAVE;
-- 写入my.cnf永久生效(重启不丢失)
[mysqld]
slave_parallel_workers = 8
slave_parallel_type = LOGICAL_CLOCK
slave_preserve_commit_order = 1
slave_transaction_retries = 102. MySQL 5.6(老版本兼容)
STOP SLAVE;
-- 按库并行(适合单库多表场景)
SET GLOBAL slave_parallel_workers = 4;
SET GLOBAL slave_parallel_type = 'DATABASE';
START SLAVE;维度 2:主库 binlog 配置优化(减少同步压力)
1. 优化 binlog 格式(优先 ROW 模式)
银行核心业务若仍用STATEMENT(SBR),复杂 SQL(如存储过程、触发器)重放耗时极长,切换为ROW(RBR)或MIXED(MBR):
-- 主库临时生效(验证后写入my.cnf)
SET GLOBAL binlog_format = 'ROW';
-- 配套优化:仅记录变更列(减小binlog体积)
SET GLOBAL binlog_row_image = 'MINIMAL';
-- my.cnf永久配置
[mysqld]
binlog_format = ROW
binlog_row_image = MINIMAL说明:ROW 模式行级复制,从库重放无需解析 SQL,效率提升 50%+,且保障数据一致性(符合银行合规要求)。
2. 增大 binlog 缓存(减少主库磁盘 IO)
主库高写入时,小 binlog 缓存会导致频繁刷盘,增大缓存减少 IO:
-- 主库配置
[mysqld]
binlog_cache_size = 32M -- 单事务binlog缓存(默认32K,调大)
max_binlog_cache_size = 512M -- 最大缓存(避免超大事务溢出)
max_binlog_size = 2G -- 增大binlog文件大小(默认1G,减少切换频率)
sync_binlog = 100 -- 每100事务刷一次binlog(平衡性能与一致性,银行可接受)注意:sync_binlog=1是最高一致性(每次事务刷盘),但 IO 开销大;调为 100 仅牺牲 “极端崩溃下最多 100 个事务丢失”,银行可通过半同步兜底,且大幅降低主库 IO 压力。
3. 主库 binlog 传输优化(MySQL 8.0+)
若用 MySQL 8.0,启用 binlog 压缩传输,减少网络带宽占用:
SET GLOBAL binlog_transport_compression = ON;
[mysqld]
binlog_transport_compression = ON维度 3:从库资源与参数调优(释放从库性能)
银行场景常存在 “主库高配、从库低配”,需微调从库资源,无架构改动:
1. 内存优化(减少磁盘 IO)
-- 从库配置(innodb缓冲池调至物理内存70%,银行服务器内存充足)
[mysqld]
innodb_buffer_pool_size = 64G -- 示例:128G内存的从库设为80G
innodb_log_buffer_size = 64M -- 增大redo log缓存
join_buffer_size = 4M -- 提升关联查询效率(SQL重放用)
sort_buffer_size = 4M -- 提升排序效率2. 磁盘 IO 优化(从库刷盘提速)
[mysqld]
innodb_flush_neighbors = 0 -- SSD磁盘关闭邻接页刷新(机械盘可设为1)
innodb_io_capacity = 2000 -- 适配SSD IO能力(默认200,调大)
innodb_io_capacity_max = 4000 -- 最大IO能力
innodb_flush_log_at_trx_commit = 2 -- 从库无需严格刷盘(每秒刷一次,提升性能)3. 关闭从库非必要功能(减少资源抢占)
-- 从库临时关闭慢查询日志(重放完成后可恢复)
SET GLOBAL slow_query_log = OFF;
-- 关闭审计日志/监控采集(非核心)
-- 禁止从库对外提供读服务(避免查询抢占SQL线程资源)
SET GLOBAL read_only = ON;维度 4:同步模式与网络优化
1. 半同步复制调优(银行主流同步模式)
若主从用半同步,避免频繁降级为异步,平衡一致性与性能:
-- 主库配置
[mysqld]
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_master_timeout = 5000 -- 超时5秒降级(默认10秒,缩短等待)
rpl_semi_sync_master_wait_for_slave_count = 1 -- 仅等1个从库确认(减少等待)
-- 从库配置
rpl_semi_sync_slave_enabled = 12. 网络优化(主从内网调优)
主从部署在同一机房 / 可用区(避免跨地域延迟,银行内网调整无架构改动);
主从之间开启
TCP_NODELAY(关闭 Nagle 算法,减少网络延迟):
# 服务器内核参数(临时生效) sysctl -w net.ipv4.tcp_nodelay=1 # 永久生效(/etc/sysctl.conf) net.ipv4.tcp_nodelay = 1临时升级主从网络带宽(如从 1Gbps 升至 10Gbps,银行内网调整成本低)。
维度 5:主库写入轻量化(最小应用改动)
在不改动架构前提下,协调应用侧做微小调整,减少同步压力:
合并小事务:银行大量小额事务(如单笔转账)可批量处理(如 100 笔合并为 1 个事务),减少 binlog 条数,从库重放效率提升数倍;
关闭非核心触发器 / 存储过程:如统计类、日志类触发器,临时关闭(核心业务触发器保留),减少 binlog 生成量;
优化慢写入 SQL:主库高耗时写入 SQL(如无索引的批量 UPDATE),优化索引后,主库写入耗时降低,同步压力同步减少。
第三步:银行生产环境操作规范
灰度执行:所有参数先在测试环境验证(模拟主库高写入),再在从库分批调整(如先调并行线程数为 4,观察 1 小时无异常再调至 8);
备份兜底:操作前备份主从配置文件(my.cnf)、关键数据(如核心表),避免参数错误导致故障;
实时监控:调整后持续监控
Seconds_Behind_Master、从库 CPU/IO、中继日志大小,确保延迟逐步下降;回滚预案:若调整后出现数据不一致 / 业务异常,立即回滚参数(恢复 my.cnf),启动主从一致性校验(pt-table-checksum)。
同步确认机制
「主库执行事务后,何时向客户端返回 “执行成功”」,直接影响数据一致性和服务可用性。
参考:MySQL 8 半同步复制详解 - 阿陶学长 - 博客园
1. 异步复制(Asynchronous Replication)
定义
主库执行事务后,立即向客户端返回成功,无需等待从库确认接收或执行 binlog。binlog 由主库异步发送给从库,从库自行重放。
工作流程
主库执行事务 → 写入 binlog → 向客户端返回 OK → 异步发送 binlog 到从库 → 从库重放。
优点
主库性能最优:无任何同步等待开销,适合高并发写入场景;
配置简单,无额外依赖。
缺点
数据一致性风险最高:主库崩溃时,已返回客户端成功的事务可能未同步到从库,导致数据丢失;
从库延迟可能较大(如主库高并发写入时,binlog 堆积)。
适用场景
非核心业务(如日志存储、统计分析);
对数据一致性要求低,优先保障主库性能。
配置
默认的主从复制模式,无需额外配置(仅需基础主从配置)。
2. 半同步复制(Semi-Synchronous Replication)
定义
主库执行事务后,需等待 至少一个从库确认接收并写入中继日志(relay log),才向客户端返回成功。若超过超时时间(默认 10 秒)仍未收到确认,自动降级为异步复制。
核心依赖
需启用 MySQL 半同步插件(semisync_master 主库插件、semisync_slave 从库插件),MySQL 5.5+ 支持。
工作流程
主库执行事务 → 写入 binlog → 等待从库确认接收 binlog 并写入中继日志 → 收到确认后向客户端返回 OK → 从库重放中继日志。
优点
数据一致性保障:主库崩溃时,已返回成功的事务至少在一个从库上存在,避免数据丢失;
兼顾性能与一致性:仅需等待从库接收确认,无需等待重放完成,性能开销可控。
缺点
主库性能略有下降(需等待从库确认,增加延迟);
若所有从库均故障,主库会降级为异步复制,仍有少量数据丢失风险。
配置方式
-- 主库配置
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; # 安装插件
SET GLOBAL rpl_semi_sync_master_enabled = 1; # 启用半同步
SET GLOBAL rpl_semi_sync_master_timeout = 10000; # 超时时间(10秒,单位毫秒)
-- 从库配置
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
-- 重启从库 IO 线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;适用场景
核心业务(如电商订单、支付),需保障数据一致性,同时容忍轻微性能开销;
高可用架构(如主从切换),需减少故障转移时的数据丢失。
3. 全同步复制(Fully Synchronous Replication)
定义
主库执行事务后,需等待 所有从库确认执行完事务并写入磁盘,才向客户端返回成功。数据一致性最高,但性能开销最大。
核心依赖
MySQL 5.7+ 支持(需启用 group_replication 插件,或使用 InnoDB Cluster),本质是半同步复制的强化版。
工作流程
主库执行事务 → 写入 binlog → 等待所有从库接收 binlog、重放完成并持久化 → 收到所有确认后向客户端返回 OK。
优点
数据一致性最高:主从数据实时一致,无任何数据丢失风险;
故障转移无数据差异:从库可直接切换为主库,无需数据补全。
缺点
主库性能开销大:需等待所有从库执行完成,写入延迟显著增加;
可用性降低:若任一从库故障,主库会阻塞等待,直到从库恢复或超时。
配置方式
(基于 MySQL Group Replication 实现,简化配置)
-- 主库/从库均需配置
[mysqld]
server-id = 1 # 唯一 ID
gtid_mode = ON # 启用 GTID
enforce_gtid_consistency = ON
plugin-load-add = group_replication.so
group_replication_group_name = "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot = OFF
group_replication_local_address = "主库IP:33061"
group_replication_group_seeds = "主库IP:33061,从库1IP:33061,从库2IP:33061"
group_replication_bootstrap_group = OFF # 仅主库首次启动设为 ON适用场景
超高一致性要求的核心业务(如金融交易、核心账户);
数据不允许任何丢失,且能接受主库性能下降的场景。
Redis
Redis做过哪些优化?
如何查看Redis的集群信息?
查看集群的整体信息:
CLUSTER INFO该命令会返回集群的健康状况、主节点的状态、分片的信息等,比如:
cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3查看集群的节点信息:
CLUSTER NODES这个命令会列出集群中所有节点的详细信息,如节点 ID、角色(主或从)、连接状态等。例如:
02d1608b7eaf869b7272f8c231157ccf655706f4 192.168.0.1:7000 master - 0 0 0 connected 0-5460 0c5191a23ea8e5044efb3f88c775169dbb03e5fa 192.168.0.2:7001 slave 02d1608b7eaf869b7272f8c231157ccf655706f4 01592468000000 1 connected 6f35a9a5cd755d16f953df946aa8b36fbb9638d2 192.168.0.3:7002 master - 0 1592468000000 2 connected 5461-10922加入新节点到集群: 可以先在新节点上启动 Redis 实例,然后执行:
redis-cli -h <新节点IP> -p <新节点端口> cluster meet <现有节点IP> <现有节点端口>第三方工具:
Redis-Cluster-Manager:这是一个第三方工具,可以帮助你更直观地管理和查看 Redis 集群状态。Redis Desktop Manager (RDM):一个支持 Redis 集群的 GUI 工具,可以用来直观地查看集群节点、键值等信息。
查看 Redis 日志: Redis 集群的日志文件通常会记录集群状态的变化,例如节点失败、重新分片等。通过查看 Redis 的日志文件,也可以获得集群运行状况的信息。日志文件位置通常在
redis.conf配置中指定:tail -f /var/log/redis/redis-server.log使用
INFO命令查看节点状态: 在每个节点上执行:INFO REPLICATION这会返回每个节点的复制状态,包括主从关系、同步状态等。对于集群模式,主节点和从节点的状态会被列出。
缓存穿透、缓存击穿、缓存雪崩(常问)
必会,略
✅ K8S
HPA
HPA是啥:HPA 的核心作用是基于监控指标动态调整 Pod 副本数,比如 Deployment、ReplicaSet 这些可扩缩资源,最终让服务规模匹配实际负载
安装
Metrics-server:Metrics-server是一个扩展的APIServer,Kubeadm默认是不部署的HPA扩缩容算法: 期望副本数 =ceil[当前副本数 * (当前指标 / 期望指标)]
pod处于pending状态怎么处理(常问)
Pod的创建过程(常问)
太熟悉了,暂略
Pod的生命周期(常问)
太熟悉了,暂略
PV 和 PVC 后端使用的是什么
1. 云厂商托管存储(公有云 / 混合云首选)
银行若使用公有云(如阿里云、AWS)或云厂商托管的私有云,优先选择云原生存储,无需自建存储集群,运维成本低且符合金融级可靠性要求。
2. 开源分布式存储(私有云 / 自建机房首选)
银行若采用私有云 / 自建机房,需自建分布式存储,以下是最常用的类型:
(1)NFS(网络文件系统)
类型:文件存储,PV 类型
kubernetes.io/nfs;核心特点:配置简单、成本低、支持多节点读写(ReadWriteMany);
适用场景:非核心业务(如日志、报表、配置文件)、开发测试环境;
配置示例(NFS PV):
apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv spec: capacity: storage: 50Gi accessModes: - ReadWriteMany # 多节点读写(NFS核心优势) persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: server: 192.168.1.100 # NFS服务器IP path: /data/nfs/k8s # NFS共享目录
(2)Ceph(分布式存储,金融级首选)
Ceph 是银行私有云最常用的分布式存储,支持三种模式:
3. PVC 关联后端存储的两种方式
1. 静态绑定(手动创建 PV)
流程:管理员先创建 PV(指定后端存储,如阿里云盘、NFS)→ 用户创建 PVC,声明存储大小、访问模式、存储类 → K8s 匹配 PV 与 PVC,绑定后 Pod 挂载 PVC 使用;
适用场景:银行核心业务(需严格管控存储资源、合规审计)、定制化存储配置。
PVC 配置示例(绑定 NFS PV):
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 50Gi storageClassName: nfs # 匹配PV的存储类
2. 动态供应(自动创建 PV)
流程:管理员创建 StorageClass(关联后端存储插件 / Provisioner)→ 用户创建 PVC 并指定
storageClassName→ K8s 自动创建 PV 并绑定 PVC,无需手动创建 PV;适用场景:非核心业务、快速部署、规模化运维。
StorageClass 配置示例(阿里云 ESSD 动态供应):
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: alicloud-essd
provisioner: diskplugin.csi.alibabacloud.com # 阿里云CSI驱动
parameters:
type: cloud_essd # 存储类型:ESSD云盘
fsType: ext4
reclaimPolicy: Retain # 回收策略:保留(银行合规要求,避免误删数据)
allowVolumeExpansion: true # 支持扩容PV 中挂载的 NFS 能否自动扩缩容?
K8s 原生不支持 NFS 类型 PV/PVC 的自动扩缩容
Service 的类型及作用
Secret 的类型
QOS 类型和作用
Job结束时Pod的状态
Pod之间无法连通如何排查?(常问)
在工作中K8S出现的难题(常问)
✅ Docker
Docker与传统虚拟机的区别(常问)
太熟悉了,暂略
Docker的网络模式有哪些?应用场景?(常问)
如何优化Docker镜像体积(常问)
太熟悉了,暂略
Docker常用命令
太熟悉了,暂略
Docker容器内部没有命令,要如何解决?
如何查看容器的PID
直接查看容器的 PID:
docker inspect <容器ID或名称> | grep Pid通过
docker top查看容器内进程:docker top <容器ID或名称>进入容器命名空间
✅ ELK
ELK 是如何部署的,如何采集k8s中的业务日志?
ELK 日志平台在我们的项目中,通常是部署在集群外部(单独的日志集群),原因如下:
日志隔离
日志数据量大(尤其直播项目,弹幕、礼物、消息量极高),如果部署在应用集群内部,会影响业务节点性能。
外部独立
Elasticsearch集群可以横向扩展,保证索引写入和查询效率。
数据收集方式:
业务
Pod内通过Filebeat将日志收集到Logstash/Elasticsearch。Logstash负责清洗和格式化,再写入Elasticsearch。Kibana用于可视化分析和排障。
高可用:
Elasticsearch集群通常部署 3 节点以上,并开启副本分片。支持滚动升级、集群扩容和灾备。
ELK主要监控的什么?
业务日志、中间件日志
✅ Prometheus
Prometheus日常巡检都做什么?巡检会关注哪些指标?
监控 MySQL 指标: 第一步:安装并配置
mysqld_exporter# 下载最新版本(根据系统架构选择,示例为 Linux x86_64) wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz # 解压并部署 tar -zxvf mysqld_exporter-0.14.0.linux-amd64.tar.gz mv mysqld_exporter-0.14.0.linux-amd64/mysqld_exporter /usr/local/bin/ chmod +x /usr/local/bin/mysqld_exporter第二步:MySQL 授权
exporter访问exporter需要读取 MySQL 的系统表(如information_schema、performance_schema)获取指标,需创建专用监控用户并授权:-- 登录 MySQL 执行 CREATE USER 'mysql_monitor'@'localhost' IDENTIFIED BY 'Monitor@2025'; -- 授予监控所需最小权限(无需写权限,避免安全风险) GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_monitor'@'localhost'; FLUSH PRIVILEGES;第三步:配置
prometheus在prometheus.yml中添加 MySQL 监控任务:scrape_configs: - job_name: 'mysql' static_configs: - targets: ['localhost:9104'] # mysqld_exporter 默认端口 scrape_interval: 15s # 采集间隔 metrics_path: '/metrics'第四步:关键监控指标
监控 Nginx 指标: 第一步:安装并配置
nginx-prometheus-exporter# 下载最新版本(Linux x86_64 示例) wget https://github.com/nginxinc/nginx-prometheus-exporter/releases/download/v0.11.0/nginx-prometheus-exporter_0.11.0_linux_amd64.tar.gz # 解压并部署 tar -zxvf nginx-prometheus-exporter_0.11.0_linux_amd64.tar.gz mv nginx-prometheus-exporter /usr/local/bin/ chmod +x /usr/local/bin/nginx-prometheus-exporter第二步:配置 Nginx 暴露监控指标 需启用 Nginx
stub_status模块(默认已编译,需在配置中开启):http { # 添加监控端点配置 server { listen 8080; server_name localhost; allow 127.0.0.1; # 仅允许本地访问 deny all; location /stub_status { stub_status on; # 暴露 Nginx 基础状态指标 access_log off; } } }重启 Nginx 使配置生效:
nginx -t # 验证配置 systemctl restart nginx第三步:启动
nginx-prometheus-exporter并配置系统服务# 创建 systemd 服务文件 cat > /etc/systemd/system/nginx-exporter.service << EOF [Unit] Description=Nginx Prometheus Exporter After=nginx.service [Service] User=root ExecStart=/usr/local/bin/nginx-prometheus-exporter --nginx.scrape-uri=http://localhost:8080/stub_status Restart=always [Install] WantedBy=multi-user.target EOF # 启动并设置开机自启 systemctl daemon-reload systemctl start nginx-exporter systemctl enable nginx-exporter第四步:配置 Prometheus 采集 Nginx 指标 在
prometheus.yml中添加 Nginx 监控任务:scrape_configs: - job_name: 'nginx' static_configs: - targets: ['localhost:9113'] # nginx-exporter 默认端口 scrape_interval: 15s第五步:关键监控指标
监控服务器基础指标(Node Exporter): 第一步:安装
node_exporter(系统基础指标采集工具)# 下载最新版本(Linux x86_64 示例) wget https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz # 解压并部署 tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz mv node_exporter-1.8.2.linux-amd64/node_exporter /usr/local/bin/ chmod +x /usr/local/bin/node_exporter第二步:配置系统服务并启动
cat > /etc/systemd/system/node-exporter.service << EOF [Unit] Description=Node Exporter After=network.target [Service] User=root ExecStart=/usr/local/bin/node_exporter Restart=always [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl start node-exporter systemctl enable node-exporter第三步:配置 Prometheus 采集服务器指标
scrape_configs: - job_name: 'node' static_configs: - targets: ['localhost:9100'] # node_exporter 默认端口 scrape_interval: 10s # 基础指标采集间隔缩短,便于快速发现问题第四步:关键监控指标
监控 Redis 指标: 第一步:安装
redis_exporterwget https://github.com/oliver006/redis_exporter/releases/download/v1.58.0/redis_exporter-v1.58.0.linux-amd64.tar.gz tar -zxvf redis_exporter-v1.58.0.linux-amd64.tar.gz mv redis_exporter-v1.58.0.linux-amd64/redis_exporter /usr/local/bin/ chmod +x /usr/local/bin/redis_exporter第二步:启动 exporter(需配置 Redis 连接信息)
# 若 Redis 有密码,启动命令添加 --redis.password=xxx nohup /usr/local/bin/redis_exporter --redis.addr=redis://localhost:6379 &第三步:Prometheus 配置(略,参考上述 MySQL/Nginx 配置模式)
第四步:关键监控指标
Prometheus 日常巡检核心动作(总结上面的段落)
监控目标可用性检查:
登录 Prometheus UI(
http://<prometheus-ip>:9090),查看Status -> Targets,确保所有 Job(node、mysql、nginx、redis 等)的State为UP,无DOWN状态。若出现
DOWN,排查网络连通性(端口是否开放)、exporter 服务是否运行、目标服务是否正常。
指标采集完整性验证:
在 Prometheus UI 输入关键指标(如
node_cpu_seconds_total、mysql_connections),查看是否有数据返回,避免指标缺失导致监控失效。
告警规则有效性检查:
查看
Alerts页面,确认无异常告警(Critical 级告警需立即处理,Warning 级需跟踪)。定期测试告警通道(如邮件、钉钉、企业微信),确保告警能及时送达。
存储与性能优化:
检查 Prometheus 存储目录空间(默认
/data),避免数据过多导致磁盘满;调整
retention_time(数据保留时间),平衡存储成本与历史数据需求;查看 Prometheus 进程 CPU/内存使用率,若过高可优化采集间隔或过滤无用指标。
历史数据趋势分析:
通过
Graph页面查看核心指标的历史趋势(如近 7 天的 CPU 使用率、QPS 变化),识别潜在瓶颈(如业务峰值时段的资源不足问题)。
prometheus 如何监控k8s集群
以下是基于 Prometheus + Grafana + Metrics Server + 各类 Exporter 的完整监控方案,包含具体部署步骤、关键指标:
一、核心监控对象与指标分类
监控对象
集群层面:整体资源利用率、节点健康状态、控制器(Deployment/StatefulSet)状态、命名空间资源配额。
节点层面:CPU/内存/磁盘/网络使用率、节点状态(Ready/NotReady)、容器运行时状态(Docker/Containerd)。
Pod/容器层面:CPU/内存/磁盘IO/网络IO使用率、Pod重启次数、容器状态(Running/CrashLoopBackOff)。
服务层面:Service 访问量(QPS)、响应延迟、错误率、Ingress 流量。
自定义指标:业务QPS、接口耗时、队列长度、数据库连接数等。
指标来源
K8s 内置指标:通过
Metrics Server采集,如节点/Pod的CPU、内存使用量。容器指标:通过
cAdvisor(K8s 内置,嵌入 kubelet)采集容器层面指标。集群对象指标:通过
kube-state-metrics采集 K8s 对象(Pod、Deployment、Service)的状态指标。自定义指标:通过业务埋点(如 Prometheus Client Library)或自定义 Exporter 采集。
二、核心监控工具链
核心组件
工具链关系
K8s 集群(节点/Pod/容器)→ Metrics Server/cAdvisor/kube-state-metrics → Prometheus(存储/查询)→ Grafana(可视化) ↓ Alertmanager(告警)
三、具体部署步骤
部署 Metrics Server(必选)
Metrics Server是 K8s 资源监控的基础,需先部署:
# 下载官方部署文件(兼容 K8s 1.19+)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 验证部署(确保 pods 处于 Running 状态)
kubectl get pods -n kube-system | grep metrics-server
# 测试指标采集(查看节点/Pod 资源使用)
kubectl top nodes
kubectl top pods部署 kube-state-metrics(采集 K8s 对象指标)
# 部署 kube-state-metrics(使用官方 Helm Chart 或 YAML) helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm install kube-state-metrics prometheus-community/kube-state-metrics -n monitoring --create-namespace # 验证部署 kubectl get pods -n monitoring | grep kube-state-metrics部署 Prometheus + Grafana(核心监控)
推荐使用 Prometheus Operator 部署(简化配置和管理):
# 部署 Prometheus Operator
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus-operator prometheus-community/kube-prometheus-stack -n monitoring --create-namespace
# 验证部署(包含 Prometheus、Grafana、Alertmanager、node-exporter)
kubectl get pods -n monitoring关键配置说明:
Prometheus 采集规则:默认已配置采集节点(node-exporter)、K8s 对象(kube-state-metrics)、容器(cAdvisor)指标。
Grafana 访问:通过 NodePort 或 Ingress 暴露服务:
# 暴露 Grafana 为 NodePort 服务 kubectl patch svc prometheus-operator-grafana -n monitoring -p '{"spec":{"type":"NodePort"}}' # 获取访问地址和密码 kubectl get svc -n monitoring | grep grafana kubectl get secret -n monitoring prometheus-operator-grafana -o jsonpath="{.data.admin-password}" | base64 -d
导入 Grafana K8s 监控仪表盘 Grafana 提供官方 K8s 仪表盘模板,直接导入即可:
登录 Grafana,进入「Dashboards」→「Import」。
输入仪表盘 ID:
8919(K8s 集群监控)、12974(K8s 节点详细监控)、6417(容器监控)。选择 Prometheus 数据源(默认已配置),完成导入。
四、K8s 核心监控指标
节点层面指标(node-exporter + Metrics Server)
Pod/容器层面指标(cAdvisor + Metrics Server)
控制器与服务层面指标(kube-state-metrics)
自定义业务指标(示例:Java 应用)
通过 Prometheus Client Library 埋点,采集业务指标:
4// 1. 引入依赖(Maven)
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient</artifactId>
<version>0.16.0</version>
</dependency>
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_spring_boot</artifactId>
<version>0.16.0</version>
</dependency>
// 2. 埋点示例(接口 QPS)
@RestController
public class BusinessController {
// 定义计数器指标
private static final Counter API_REQUESTS = Counter.build()
.name("business_api_requests_total")
.labelNames("endpoint", "method", "status")
.help("Total number of business API requests")
.register();
@GetMapping("/api/order")
public ResponseEntity<?> getOrder() {
// 记录请求(标签:端点、方法、状态码)
API_REQUESTS.labels("/api/order", "GET", "200").inc();
return ResponseEntity.ok("success");
}
}业务指标监控:
在 Grafana 中创建自定义仪表盘,展示
business_api_requests_total(QPS)、business_api_latency_seconds(接口延迟)等指标。配置告警:如 QPS 突降 50%、接口延迟>500ms。
五、K8s 监控告警配置
通过 Prometheus + Alertmanager 配置告警规则,示例:
配置节点 CPU 使用率过高告警
在 Prometheus 规则文件中添加:
groups:
- name: k8s_node_alerts
rules:
- alert: NodeCpuUsageHigh
expr: avg(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance) > 0.8
for: 10m
labels:
severity: warning
annotations:
summary: "节点 CPU 使用率过高"
description: "节点 {{ $labels.instance }} 的 CPU 使用率持续 10 分钟超过 80%,当前值:{{ $value | humanizePercentage }}"配置 Pod 重启次数过多告警
- alert: PodRestartTooMany
expr: sum(increase(kube_pod_restart_count[10m])) by (pod, namespace) > 3
for: 5m
labels:
severity: critical
annotations:
summary: "Pod 重启次数过多"
description: "命名空间 {{ $labels.namespace }} 的 Pod {{ $labels.pod }} 10 分钟内重启超过 3 次,可能存在异常"配置告警渠道(Alertmanager)
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'dingtalk'
receivers:
- name: 'dingtalk'
webhook_configs:
- url: 'https://oapi.dingtalk.com/robot/send?access_token=xxx' # 钉钉机器人 Token
send_resolved: true六、日常监控与巡检
集群健康状态:
查看 Grafana 仪表盘「K8s Cluster Health」,确认节点 Ready 状态、Pod 运行状态。
检查控制器(Deployment/StatefulSet)的副本数是否达标。
资源瓶颈排查:
通过「Node Details」仪表盘查看节点 CPU/内存/磁盘使用率,识别资源紧张节点。
通过「Container Resources」仪表盘查看高资源消耗容器,优化资源配置(requests/limits)。
业务指标监控:
关注自定义业务仪表盘的 QPS、延迟、错误率,确认业务正常运行。
对比历史数据,识别业务峰值时段,提前扩容资源。
告警处理:
定期查看 Alertmanager 告警记录,处理 Critical 级告警(如节点不可用、Pod 频繁重启)。
优化告警规则,避免误告警(如调整阈值、增加持续时间)。
Prometheus 部署方式?(接上文,k8s部署在集群内还是集群外?)
Prometheus 是部署在 Kubernetes 集群内的,原因如下:
集群内监控优势:
可以直接通过
ServiceMonitor/PodMonitor采集集群内节点、Pod、Service指标。与
HPA/自定义指标适配器集成,支持业务指标驱动的自动扩缩容。利用
StatefulSet或Operator管理Prometheus实例,保证高可用和数据持久化(PV/PVC)。
高可用:
部署 双实例
Prometheus,通过Alertmanager实现告警抑制和通知路由。核心指标(推流延迟、在线人数、Redis 队列长度)通过
Prometheus Adapter提供给HPA,实时调度Pod。
✅ 场景题:
怎么看待运维这个岗位的?与传统岗位有什么不一样?(常问)
未来三到五年职业规划是什么?(常问)
对于下一份工作有什么规划?(与上一个问题类似,常问)
为什么转行业?平时是如何学习的?(常问)
✅ 网络:
常见的HTTP请求方式
幂等:指一个操作执行一次或多次的效果是相同的,不会因为重复执行而产生副作用。 简单说:重复请求不会改变结果。
OSI模型(常问)
核心考点:
七层分层(从下到上):物理层→数据链路层→网络层→传输层→会话层→表示层→应用层(要求能快速说出,且对应核心功能)。
偏门追问:
“Docker 的 veth 设备工作在哪个层级?”(数据链路层,负责容器与 docker0 桥的二层帧转发)。
“K8s 的 Service 和 Ingress 分别对应 OSI 哪一层?”(Service 对应传输层,基于端口转发;Ingress 对应应用层,基于 HTTP/HTTPS 路径转发)。
“NFS 协议工作在哪个层级?”(应用层,所以排查 NFS 超时需先看网络层连通性,再看应用层协议交互)。